rm(list=ls())
#major required packages:
require(devtools)
devtools::install_github("HannaMeyer/CAST")
library(raster)
library(terra)
library(caret)
library(randomForest)
library(twosamples)
library(mapview)
library(sf)
library(CAST)
library(tmap)
library(rprojroot)
# create a string containing the current working directory
wd = paste0(find_rstudio_root_file(),"/ml_session/data/")Machine learning for remote sensing applications
Mapping the MarburgOpenForest
Introduction
In this tutorial we will go through the basic workflow of training machine learning models for spatial mapping based on remote sensing. To do this we will look at two case studies located in the MarburgOpenForest in Germany: one has the aim to produce a land cover map including different tree species; the other aims at producing a map of Leaf Area Index.
Based on “default” models, we will further discuss the relevance of different validation strategies and the area of applicability.
How to start
For this tutorial we need the raster package for processing of the satellite data (note: needs to be replaced by terra soon) as well as the caret package as a wrapper for machine learning (here: randomForest) algorithms. Sf is used for handling of the training data available as vector data (polygons). Mapview is used for spatial visualization of the data. CAST will be used to account for spatial dependencies during model validation as well as for the estimation of the AOA.
Case study 1: land cover classification
Data preparation
To start with, let’s load and explore the remote sensing raster data as well as the vector data that include the training sites.
Raster data (predictor variables)
mof_sen <- rast(paste0(wd,"sentinel_uniwald.grd"))
print(mof_sen)class : SpatRaster
dimensions : 522, 588, 10 (nrow, ncol, nlyr)
resolution : 10, 10 (x, y)
extent : 474200, 480080, 5629540, 5634760 (xmin, xmax, ymin, ymax)
coord. ref. : +proj=utm +zone=32 +datum=WGS84 +units=m +no_defs
source : sentinel_uniwald.grd
names : T32UM~1_B02, T32UM~1_B03, T32UM~1_B04, T32UM~1_B05, T32UM~1_B06, T32UM~1_B07, ...
min values : 723, 514, 294, 341.8125, 396.9375, 440.8125, ...
max values : 8325, 9087, 13810, 7368.7500, 8683.8125, 9602.3125, ... The raster data contain a subset of the optical data from Sentinel-2 (see band information here: https://en.wikipedia.org/wiki/Sentinel-2) given in scaled reflectances (B02-B11). In addition,the NDVI was calculated. Let’s plot the data to get an idea how the variables look like.
plot(mof_sen)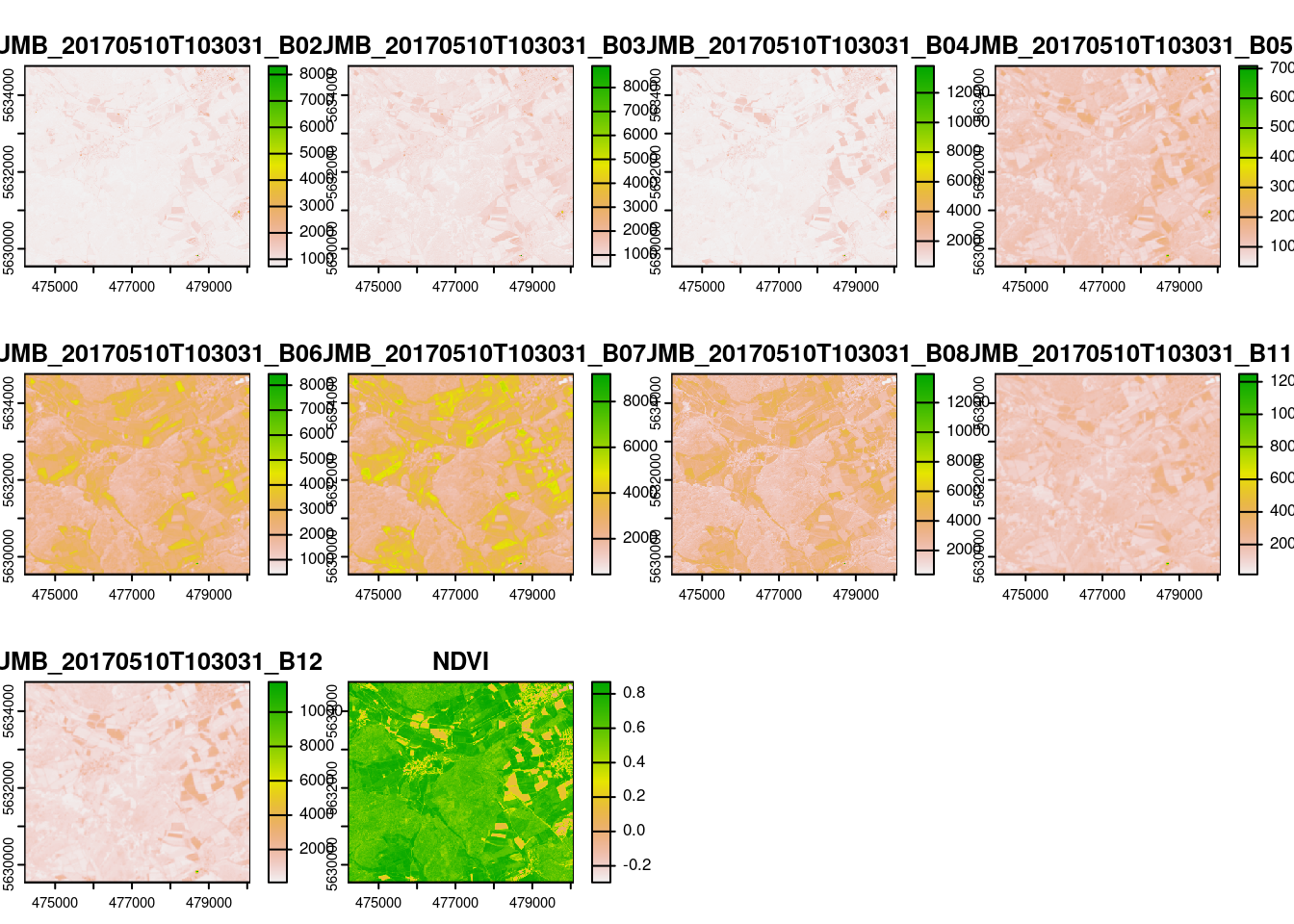
plotRGB(mof_sen,r=3,g=2,b=1,stretch="lin")
Vector data (Response variable)
The vector file is read as sf object. It contains the training sites that will be regarded here as a ground truth for the land cover classification.
trainSites <- read_sf(paste0(wd,"trainingsites_LUC.gpkg"))Using mapview we can visualize the aerial image channels in the geographical context and overlay it with the polygons. Click on the polygons to see which land cover class is assigned to a respective polygon.
mapview(raster(mof_sen[[1]]), map.types = "Esri.WorldImagery") +
mapview(trainSites)Draw training samples and extract raster information
In order to train a machine learning model between the spectral properties and the land cover class, we first need to create a data frame that contains the predictor variables at the location of the training sites as well as the corresponding class information. However, using each pixel overlapped by a polygon would lead to a overly huge dataset, therefore, we first draw training samples from the polygon. Let’s use 1000 randomly sampled (within the polygons) pixels as training data set.
trainlocations <- st_sample(trainSites,1000)
trainlocations <- st_join(st_sf(trainlocations), trainSites)
mapview(trainlocations)Next, we can extract the raster values for these locations. The resulting data frame contains the predictor variables for each training location that we can merged with the information on the land cover class from the sf object.
trainDat <- extract(mof_sen, trainlocations, df=TRUE)
trainDat <- data.frame(trainDat, trainlocations)
head(trainDat) ID T32UMB_20170510T103031_B02 T32UMB_20170510T103031_B03
1 1 768 587
2 2 832 702
3 3 852 758
4 4 779 605
5 5 801 768
6 6 849 836
T32UMB_20170510T103031_B04 T32UMB_20170510T103031_B05
1 336 572.3125
2 430 762.4375
3 475 870.1875
4 349 613.2500
5 447 905.1250
6 497 948.4375
T32UMB_20170510T103031_B06 T32UMB_20170510T103031_B07
1 1550.812 1867.500
2 2574.625 3697.875
3 2488.000 3265.250
4 1558.125 1882.562
5 1698.562 1927.875
6 3390.125 4809.188
T32UMB_20170510T103031_B08 T32UMB_20170510T103031_B11
1 1751 700.750
2 3650 1174.938
3 3145 1180.938
4 2044 812.000
5 2043 1154.812
6 4711 1597.188
T32UMB_20170510T103031_B12 NDVI id LN Type geometry
1 278.6250 0.6780067 NA 3 Duglasie POINT (476551.8 5631936)
2 521.1250 0.7892157 NA 108 Felder POINT (476460.7 5632307)
3 584.8750 0.7375690 NA 102 Felder POINT (478114.1 5631123)
4 352.6875 0.7083159 NA 3 Duglasie POINT (477072.2 5631588)
5 564.3125 0.6409639 NA 2 Buche POINT (477381.6 5632646)
6 669.2500 0.8091398 65 303 Wiese POINT (476109.1 5631682)Model training
Predictors and response
For model training we need to define the predictor and response variables. As predictors we can use basically all information from the raster stack as we might assume they could all be meaningful for the differentiation between the land cover classes. As response variable we use the “Label” column of the data frame.
predictors <- names(mof_sen)
response <- "Type"A first “default” model
We then train a Random Forest model to lean how the classes can be distinguished based on the predictors (note: other algorithms would work as well. See https://topepo.github.io/caret/available-models.html for a list of algorithms available in caret). Caret’s train function is doing this job.
So let’s see how we can then train a “default” random forest model. We specify “rf” as method, indicating that a Random Forest is applied. We reduce the number of trees (ntree) to 75 to speed things up. Note that usually a larger number (>250) is appropriate.
model <- train(trainDat[,predictors],
trainDat[,response],
method="rf",
ntree=75)
modelRandom Forest
1000 samples
10 predictor
10 classes: 'Buche', 'Duglasie', 'Eiche', 'Felder', 'Fichte', 'Laerche', 'Siedlung', 'Strasse', 'Wasser', 'Wiese'
No pre-processing
Resampling: Bootstrapped (25 reps)
Summary of sample sizes: 1000, 1000, 1000, 1000, 1000, 1000, ...
Resampling results across tuning parameters:
mtry Accuracy Kappa
2 0.8283930 0.7868652
6 0.8281409 0.7868166
10 0.8203903 0.7774163
Accuracy was used to select the optimal model using the largest value.
The final value used for the model was mtry = 2.To perform the classification we can then use the trained model and apply it to each pixel of the raster stack using the predict function.
prediction <- predict(mof_sen,model)Then we can then create a map with meaningful colors of the predicted land cover using the tmap package.
cols <- rev(c("palegreen", "blue", "grey", "red", "lightgreen", "forestgreen", "beige","brown","darkgreen","yellowgreen"))
tm_shape(prediction) +
tm_raster(palette = cols,title = "LUC")+
tm_scale_bar(bg.color="white",bg.alpha=0.75)+
tm_layout(legend.bg.color = "white",
legend.bg.alpha = 0.75)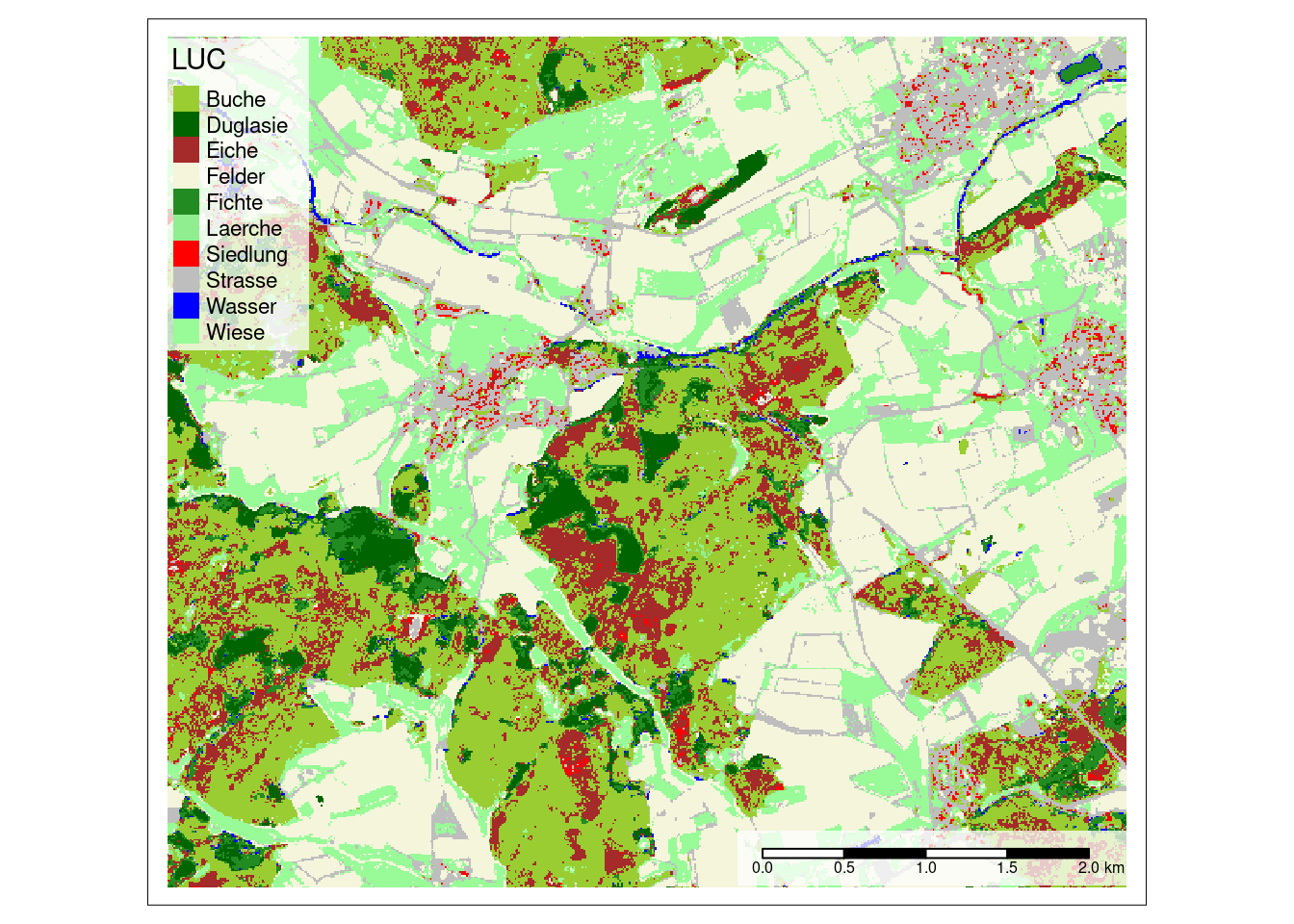
Based on this we can now discuss more advanced aspects of cross-validation for performance assessment as well as spatial variable selection strategies.
Model training with spatial CV and variable selection
Before starting model training we can specify some control settings using trainControl. For hyperparameter tuning (mtry) as well as for error assessment we use a spatial cross-validation. Here, the training data are split into 5 folds by trying to resemble the geographic distance distribution required when predicting the entire area from the trainign data,
## define prediction area:
studyArea <- as.polygons(mof_sen, values = FALSE, na.all = TRUE) |>
st_as_sf() |>
st_transform(st_crs(trainlocations))|>
st_union()
mapview(studyArea) indices <- knndm(trainlocations,studyArea,k=5)
gd <- geodist(trainlocations,studyArea,cvfolds = indices$indx_train )
plot(gd)+ scale_x_log10(labels=round)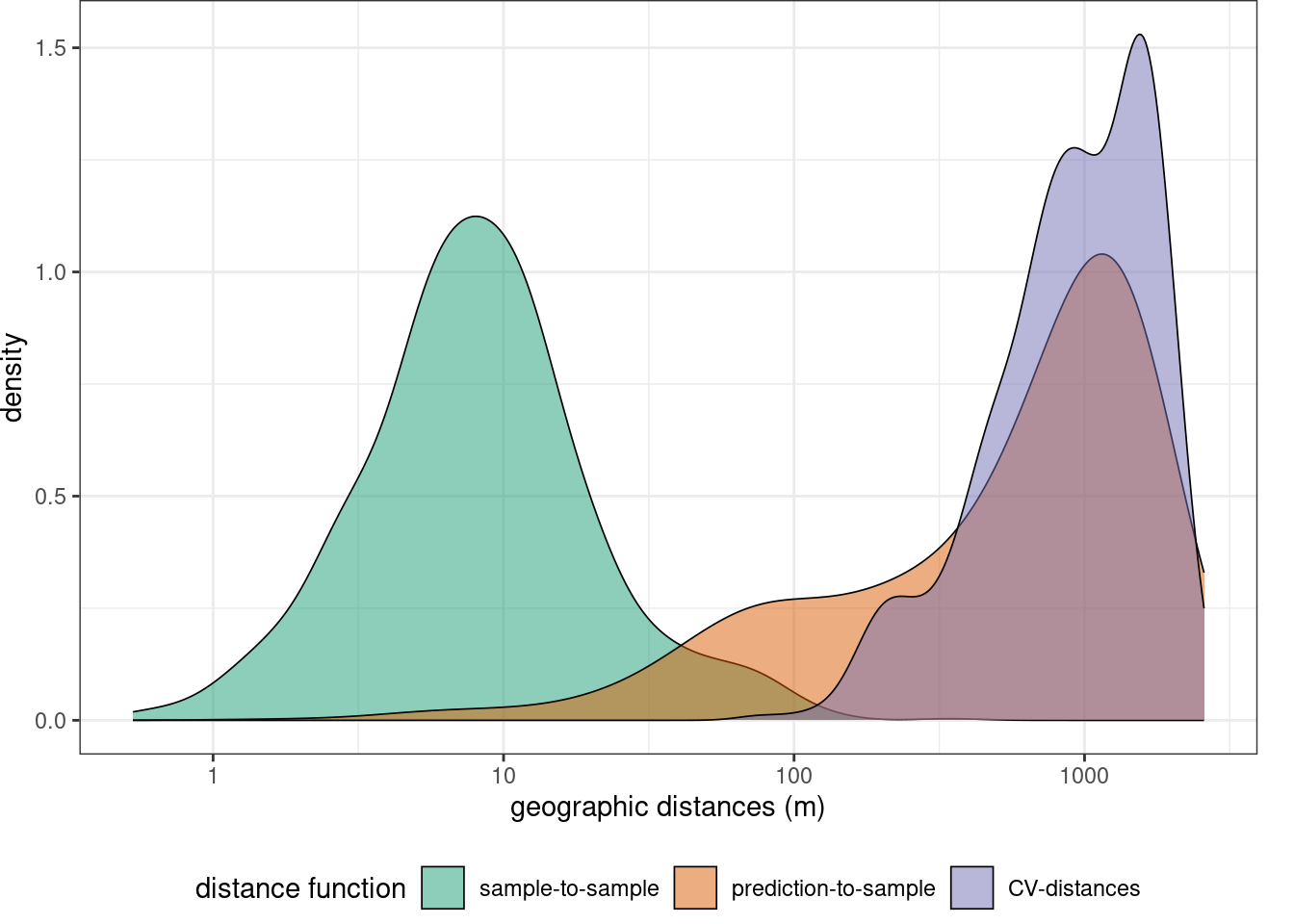
ctrl <- trainControl(method="cv",
index = indices$indx_train,
indexOut = indices$indx_test,
savePredictions = TRUE)Model training is then again performed using caret’s train function. However we use a wrapper around it that is selecting the predictor variables which are relevant for making predictions to new spatial locations (forward feature selection, fss). We use the Kappa index as metric to select the best model.
# train the model
set.seed(100)
model <- ffs(trainDat[,predictors],
trainDat[,response],
method="rf",
metric="Kappa",
trControl=ctrl,
importance=TRUE,
ntree=200,
verbose=FALSE)print(model)Selected Variables:
T32UMB_20170510T103031_B05 T32UMB_20170510T103031_B07 T32UMB_20170510T103031_B02 T32UMB_20170510T103031_B03 T32UMB_20170510T103031_B04
---
Random Forest
1000 samples
5 predictor
10 classes: 'Buche', 'Duglasie', 'Eiche', 'Felder', 'Fichte', 'Laerche', 'Siedlung', 'Strasse', 'Wasser', 'Wiese'
No pre-processing
Resampling: Cross-Validated (10 fold)
Summary of sample sizes: 826, 817, 685, 870, 802
Resampling results across tuning parameters:
mtry Accuracy Kappa
2 0.7805363 0.5867898
3 0.7659117 0.5614506
5 0.7330196 0.5034335
Kappa was used to select the optimal model using the largest value.
The final value used for the model was mtry = 2.plot(varImp(model))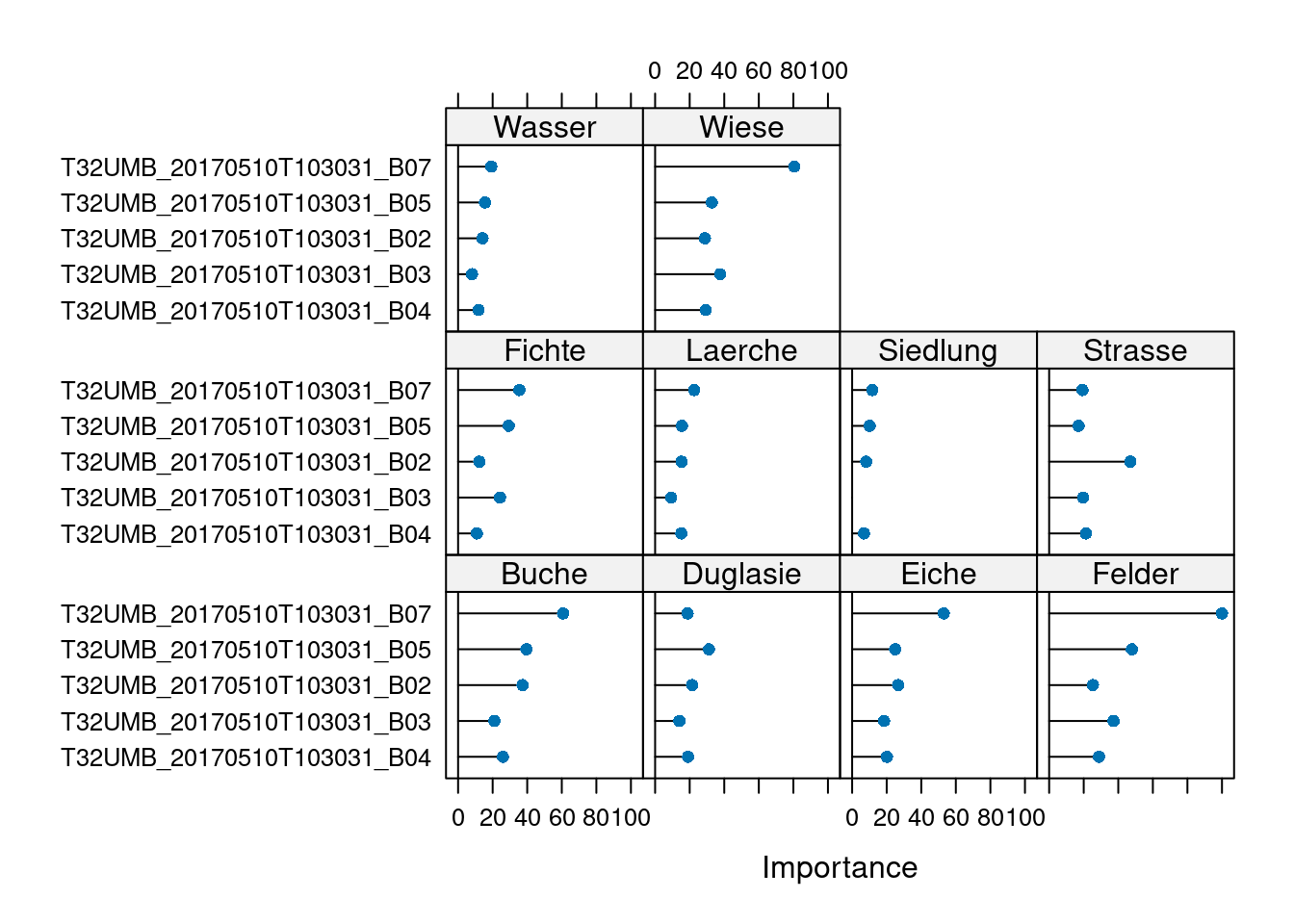
Model validation
When we print the model (see above) we get a summary of the prediction performance as the average Kappa and Accuracy of the three spatial folds. Looking at all cross-validated predictions together we can get the “global” model performance.
# get all cross-validated predictions:
cvPredictions <- model$pred[model$pred$mtry==model$bestTune$mtry,]
# calculate cross table:
table(cvPredictions$pred,cvPredictions$obs)
Buche Duglasie Eiche Felder Fichte Laerche Siedlung Strasse Wasser
Buche 5 0 7 0 6 0 0 0 0
Duglasie 0 4 0 0 2 0 0 0 0
Eiche 0 0 1 0 2 0 0 0 0
Felder 4 0 0 279 0 0 0 10 0
Fichte 1 0 0 0 1 0 0 0 0
Laerche 0 0 0 0 0 0 0 0 0
Siedlung 0 0 0 2 0 0 0 1 0
Strasse 0 0 0 20 0 0 0 34 0
Wasser 0 0 0 0 3 0 0 0 0
Wiese 0 0 0 28 0 0 0 5 0
Wiese
Buche 3
Duglasie 0
Eiche 0
Felder 8
Fichte 0
Laerche 0
Siedlung 0
Strasse 9
Wasser 0
Wiese 76Visualize the final model predictions
prediction <- predict(mof_sen,model)
cols <- rev(c("palegreen", "blue", "grey", "red", "lightgreen", "forestgreen", "beige","brown","darkgreen","yellowgreen"))
tm_shape(prediction) +
tm_raster(palette = cols,title = "LUC")+
tm_scale_bar(bg.color="white",bg.alpha=0.75)+
tm_layout(legend.bg.color = "white",
legend.bg.alpha = 0.75)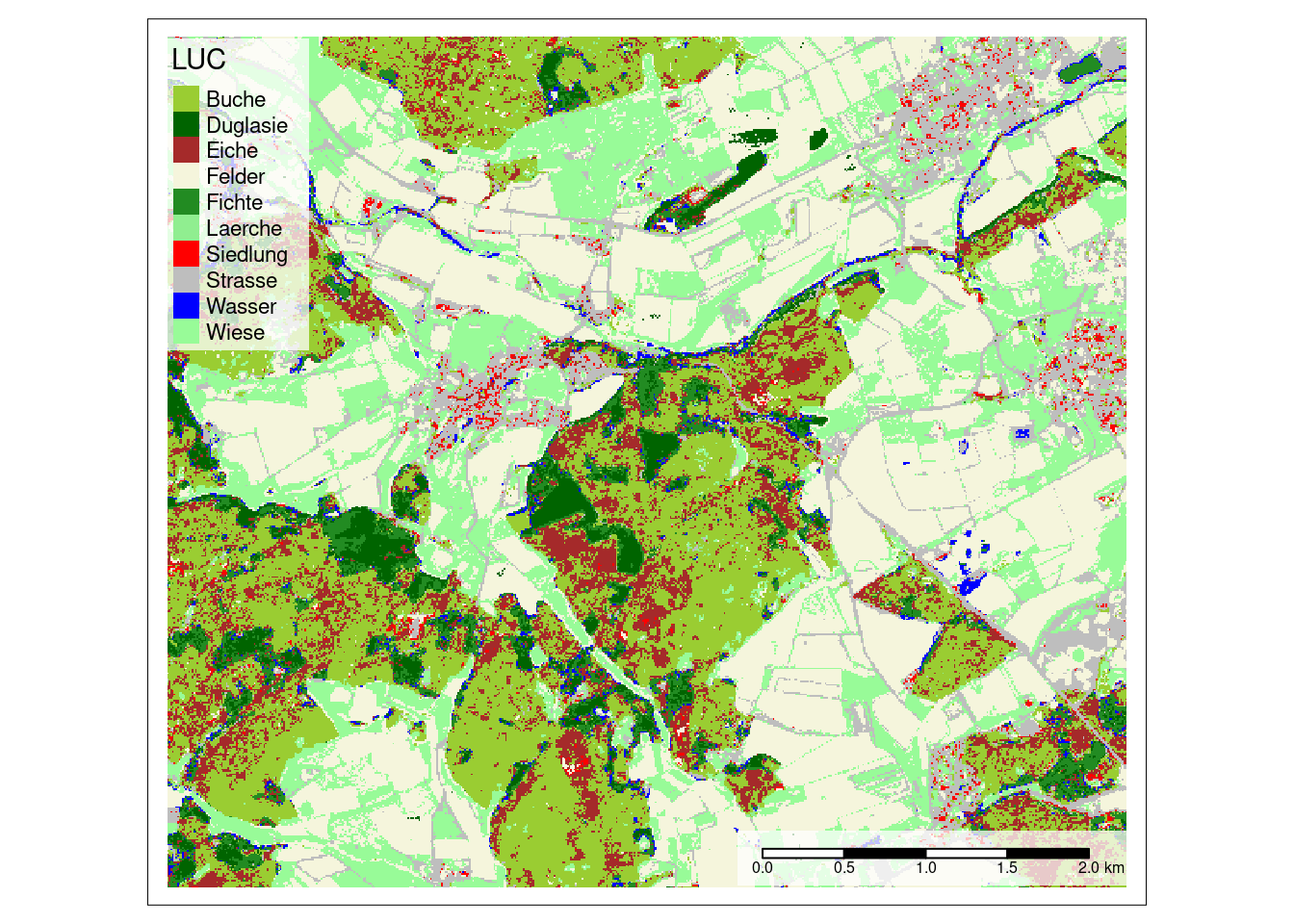
Area of Applicability
We have seen that technically, the trained model can be applied to the entire area of interest (and beyond…as long as the sentinel predictors are available which they are, even globally). But we should assess if we SHOULD apply our model to the entire area. The model should only be applied to locations that feature predictor properties that are comparable to those of the training data. If dissimilarity to the training data is larger than the dissimmilarity within the training data, the model should not be applied to this location.
AOA <- aoa(mof_sen,model)
|
| | 0%
|
| | 1%
|
|= | 1%
|
|= | 2%
|
|== | 2%
|
|== | 3%
|
|== | 4%
|
|=== | 4%
|
|=== | 5%
|
|==== | 5%
|
|==== | 6%
|
|===== | 6%
|
|===== | 7%
|
|===== | 8%
|
|====== | 8%
|
|====== | 9%
|
|======= | 9%
|
|======= | 10%
|
|======= | 11%
|
|======== | 11%
|
|======== | 12%
|
|========= | 12%
|
|========= | 13%
|
|========= | 14%
|
|========== | 14%
|
|========== | 15%
|
|=========== | 15%
|
|=========== | 16%
|
|============ | 16%
|
|============ | 17%
|
|============ | 18%
|
|============= | 18%
|
|============= | 19%
|
|============== | 19%
|
|============== | 20%
|
|============== | 21%
|
|=============== | 21%
|
|=============== | 22%
|
|================ | 22%
|
|================ | 23%
|
|================ | 24%
|
|================= | 24%
|
|================= | 25%
|
|================== | 25%
|
|================== | 26%
|
|=================== | 26%
|
|=================== | 27%
|
|=================== | 28%
|
|==================== | 28%
|
|==================== | 29%
|
|===================== | 29%
|
|===================== | 30%
|
|===================== | 31%
|
|====================== | 31%
|
|====================== | 32%
|
|======================= | 32%
|
|======================= | 33%
|
|======================= | 34%
|
|======================== | 34%
|
|======================== | 35%
|
|========================= | 35%
|
|========================= | 36%
|
|========================== | 36%
|
|========================== | 37%
|
|========================== | 38%
|
|=========================== | 38%
|
|=========================== | 39%
|
|============================ | 39%
|
|============================ | 40%
|
|============================ | 41%
|
|============================= | 41%
|
|============================= | 42%
|
|============================== | 42%
|
|============================== | 43%
|
|============================== | 44%
|
|=============================== | 44%
|
|=============================== | 45%
|
|================================ | 45%
|
|================================ | 46%
|
|================================= | 46%
|
|================================= | 47%
|
|================================= | 48%
|
|================================== | 48%
|
|================================== | 49%
|
|=================================== | 49%
|
|=================================== | 50%
|
|=================================== | 51%
|
|==================================== | 51%
|
|==================================== | 52%
|
|===================================== | 52%
|
|===================================== | 53%
|
|===================================== | 54%
|
|====================================== | 54%
|
|====================================== | 55%
|
|======================================= | 55%
|
|======================================= | 56%
|
|======================================== | 56%
|
|======================================== | 57%
|
|======================================== | 58%
|
|========================================= | 58%
|
|========================================= | 59%
|
|========================================== | 59%
|
|========================================== | 60%
|
|========================================== | 61%
|
|=========================================== | 61%
|
|=========================================== | 62%
|
|============================================ | 62%
|
|============================================ | 63%
|
|============================================ | 64%
|
|============================================= | 64%
|
|============================================= | 65%
|
|============================================== | 65%
|
|============================================== | 66%
|
|=============================================== | 66%
|
|=============================================== | 67%
|
|=============================================== | 68%
|
|================================================ | 68%
|
|================================================ | 69%
|
|================================================= | 69%
|
|================================================= | 70%
|
|================================================= | 71%
|
|================================================== | 71%
|
|================================================== | 72%
|
|=================================================== | 72%
|
|=================================================== | 73%
|
|=================================================== | 74%
|
|==================================================== | 74%
|
|==================================================== | 75%
|
|===================================================== | 75%
|
|===================================================== | 76%
|
|====================================================== | 76%
|
|====================================================== | 77%
|
|====================================================== | 78%
|
|======================================================= | 78%
|
|======================================================= | 79%
|
|======================================================== | 79%
|
|======================================================== | 80%
|
|======================================================== | 81%
|
|========================================================= | 81%
|
|========================================================= | 82%
|
|========================================================== | 82%
|
|========================================================== | 83%
|
|========================================================== | 84%
|
|=========================================================== | 84%
|
|=========================================================== | 85%
|
|============================================================ | 85%
|
|============================================================ | 86%
|
|============================================================= | 86%
|
|============================================================= | 87%
|
|============================================================= | 88%
|
|============================================================== | 88%
|
|============================================================== | 89%
|
|=============================================================== | 89%
|
|=============================================================== | 90%
|
|=============================================================== | 91%
|
|================================================================ | 91%
|
|================================================================ | 92%
|
|================================================================= | 92%
|
|================================================================= | 93%
|
|================================================================= | 94%
|
|================================================================== | 94%
|
|================================================================== | 95%
|
|=================================================================== | 95%
|
|=================================================================== | 96%
|
|==================================================================== | 96%
|
|==================================================================== | 97%
|
|==================================================================== | 98%
|
|===================================================================== | 98%
|
|===================================================================== | 99%
|
|======================================================================| 99%
|
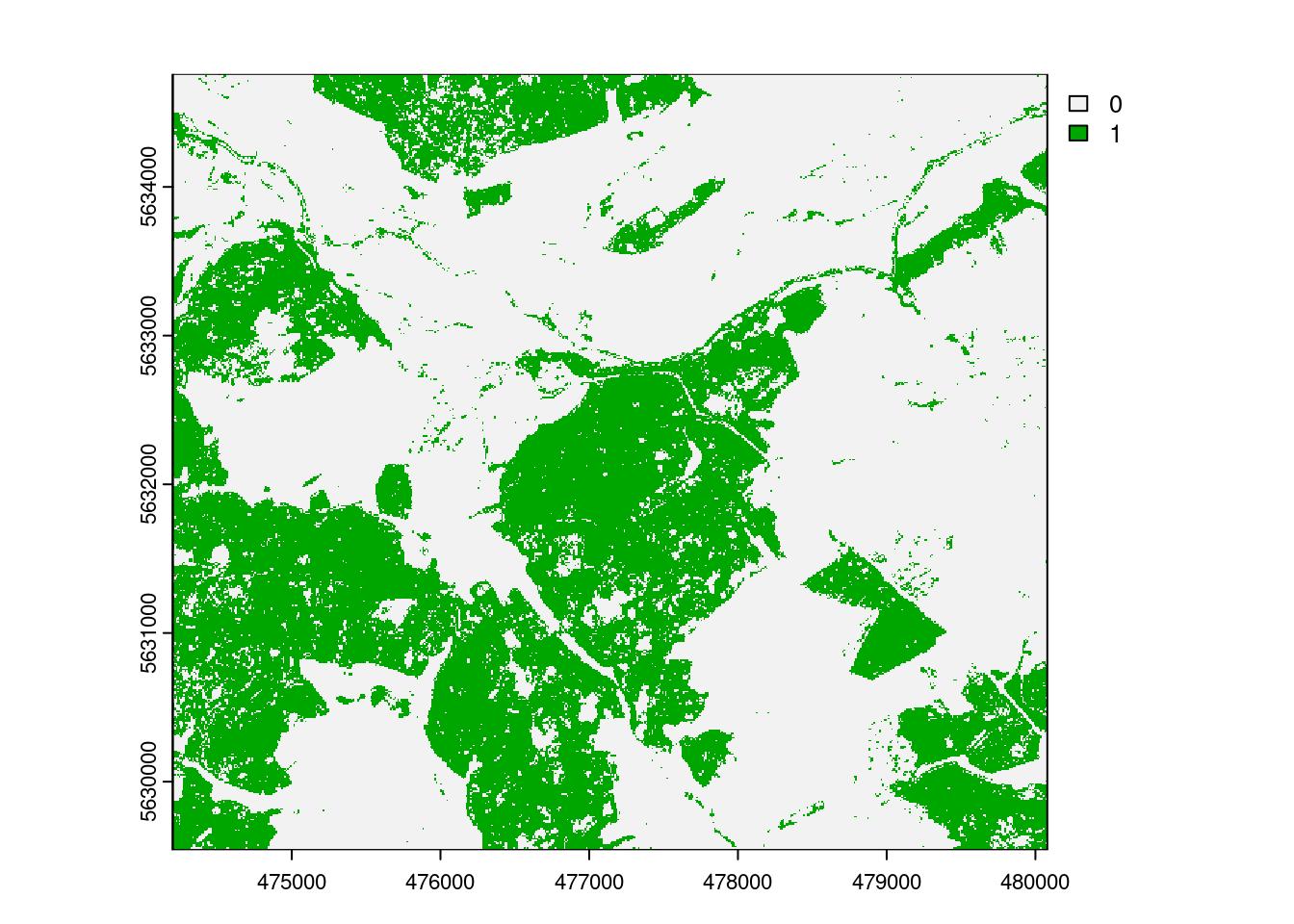
|======================================================================| 100%plot(AOA$AOA)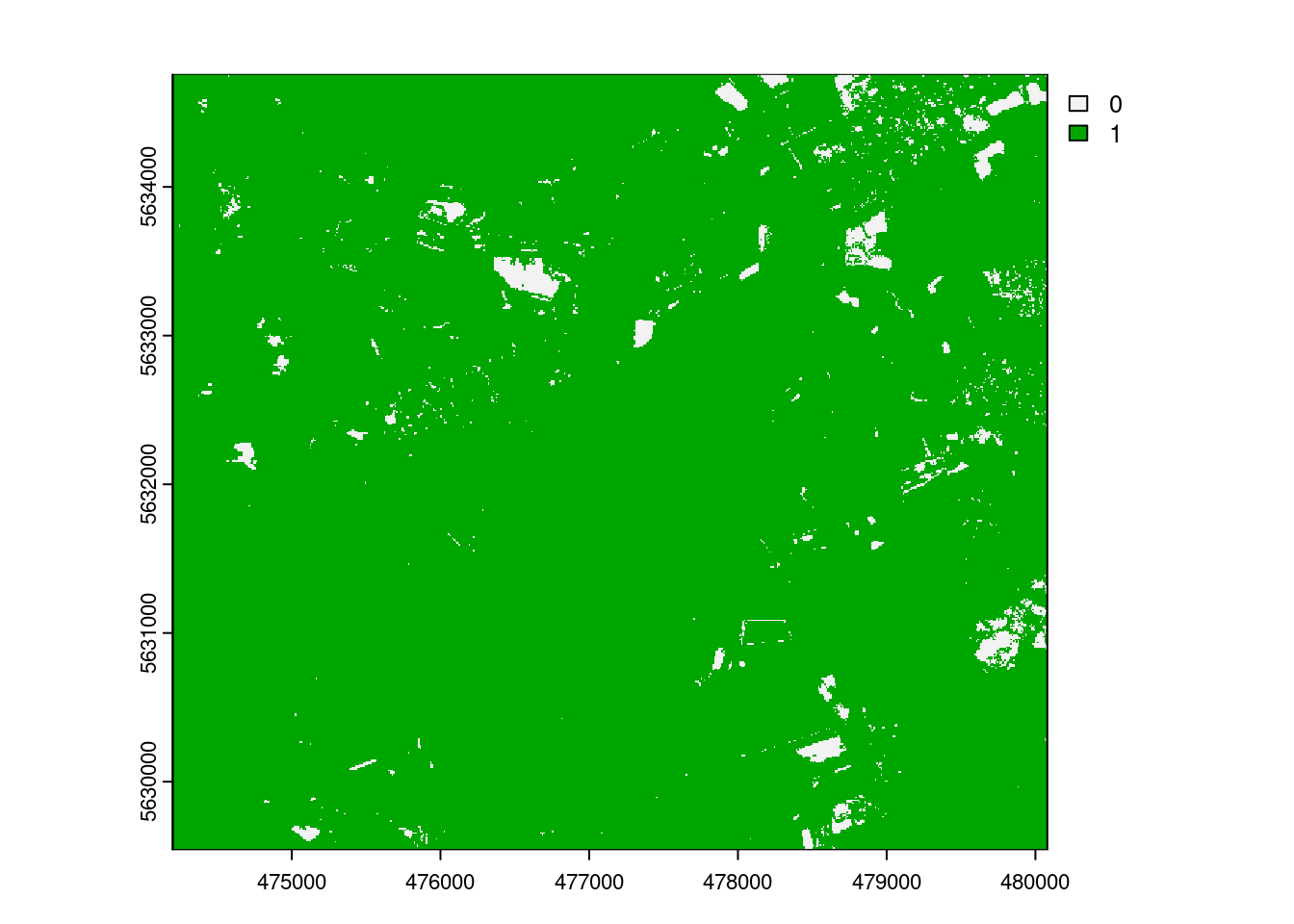
The result of the aoa function has two layers: the dissimilarity index (DI) and the area of applicability (AOA). The DI can take values from 0 to Inf, where 0 means that a location has predictor properties that are identical to properties observed in the training data. With increasing values the dissimilarity increases. The AOA has only two values: 0 and 1. 0 means that a location is outside the area of applicability, 1 means that the model is inside the area of applicability.
Case Study 2: Modelling the Leaf Area Index
In the second example we will look at a regression task: We have point measurements of Leaf area index (LAI), and, based in this, we would like to make predictions for the entire forest. Again, we will use the Sentinel data as potnetial predictors.
Prepare data
mof_sen <- rast("data/sentinel_uniwald.grd")
LAIdat <- st_read("data/trainingsites_LAI.gpkg")Reading layer `trainingsites_LAI' from data source
`/home/creu/edu/courses/EON/EON2024/ml_session/data/trainingsites_LAI.gpkg'
using driver `GPKG'
Simple feature collection with 67 features and 10 fields
Geometry type: POINT
Dimension: XY
Bounding box: xmin: 476350 ymin: 5631537 xmax: 478075 ymax: 5632765
Projected CRS: WGS 84 / UTM zone 32NtrainDat <- extract(mof_sen,LAIdat,na.rm=TRUE)
trainDat$LAI <- LAIdat$LAI
meanmodel <- mof_sen[[1]]
values(meanmodel) <- mean(trainDat$LAI)
plot(meanmodel)
randommodel <- mof_sen[[1]]
values(randommodel)<- runif(ncell(randommodel),min = 0,4)
plot(randommodel)
A simple linear model
As a simple first approach we might develop a linear model. Let’s assume a linear relationship between the NDVI and the LAI
plot(trainDat$NDVI,trainDat$LAI)
model_lm <- lm(LAI~NDVI,data=trainDat)
summary(model_lm)
Call:
lm(formula = LAI ~ NDVI, data = trainDat)
Residuals:
Min 1Q Median 3Q Max
-1.87314 -0.52143 -0.03363 0.63668 2.25252
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.8518 1.4732 -0.578 0.56515
NDVI 6.8433 2.3160 2.955 0.00435 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.8887 on 65 degrees of freedom
Multiple R-squared: 0.1184, Adjusted R-squared: 0.1049
F-statistic: 8.731 on 1 and 65 DF, p-value: 0.004354abline(model_lm,col="red")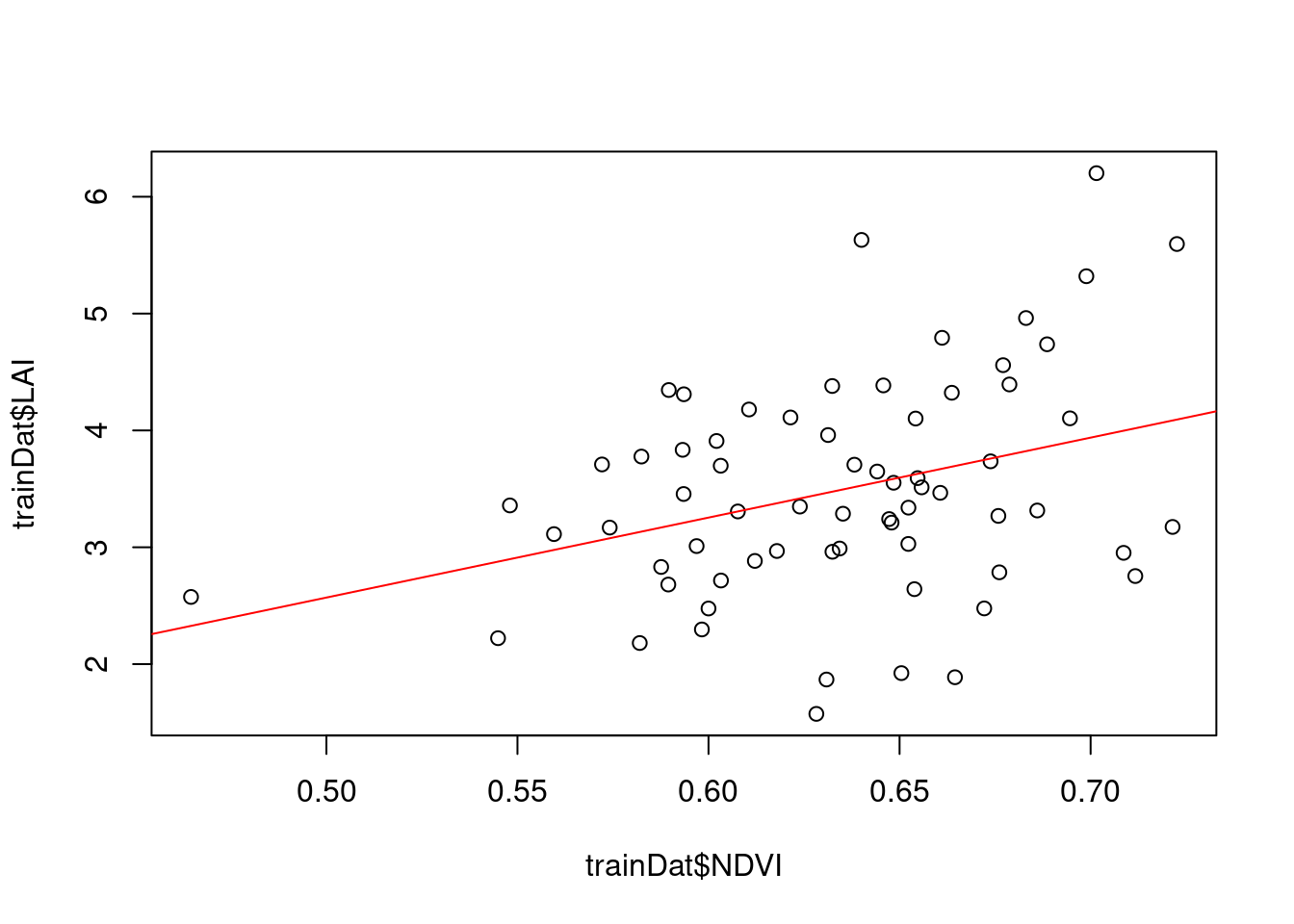
prediction_LAI <- predict(mof_sen,model_lm,na.rm=T)
plot(prediction_LAI)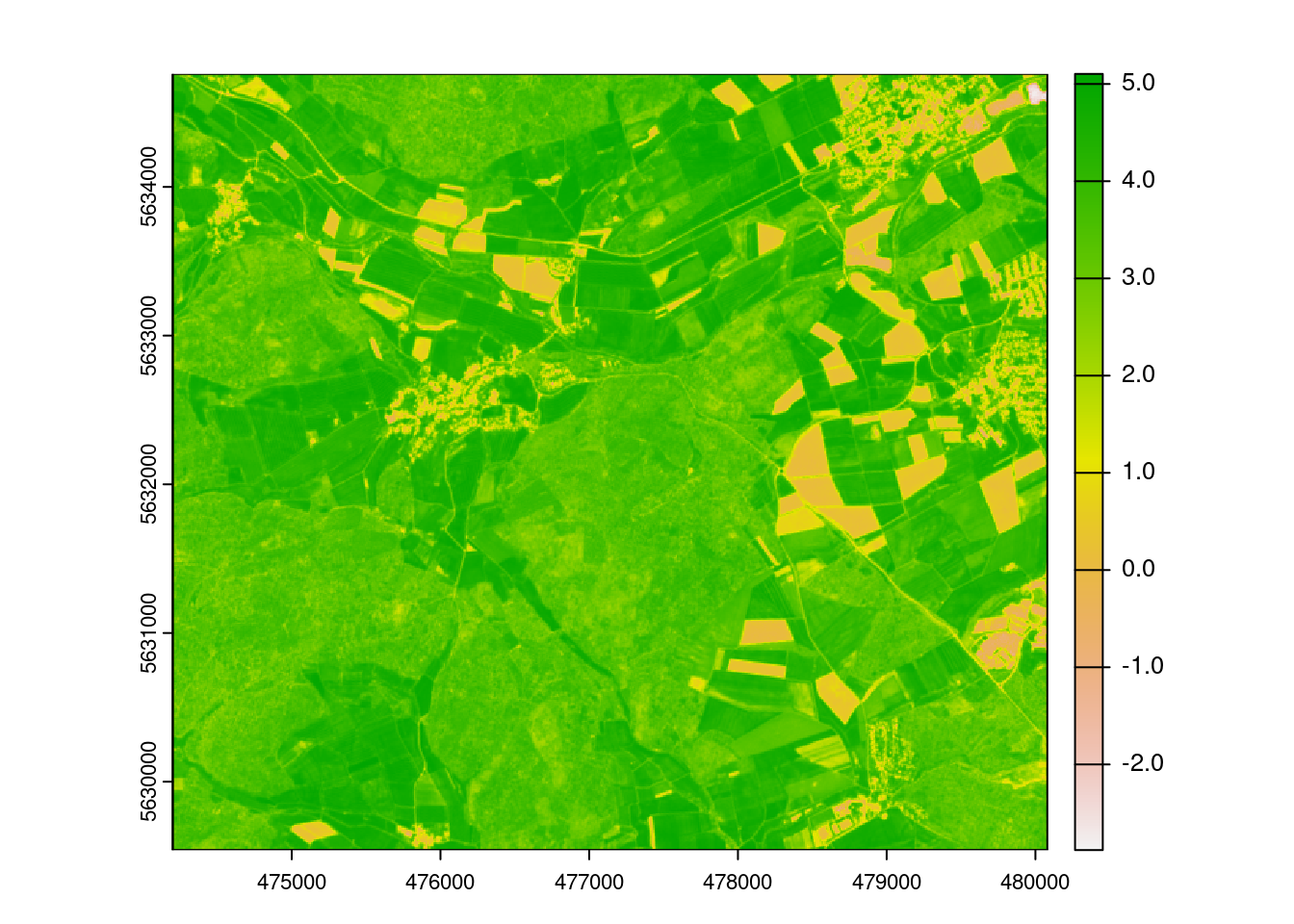
limodelpred <- -0.8518+mof_sen$NDVI*6.8433
mapview(raster(limodelpred))The machine learning way
Define CV folds
Let’s use the NNDM cross-validation approach.
studyArea <- as.polygons(mof_sen, values = FALSE, na.all = TRUE) |>
st_as_sf() |>
st_transform(st_crs(LAIdat))|>
st_union()
nndm_folds <- knndm(LAIdat,studyArea,k=3)Let’s explore the geodistance
gd <- geodist(LAIdat,studyArea,cvfolds = nndm_folds$indx_test)
plot(gd)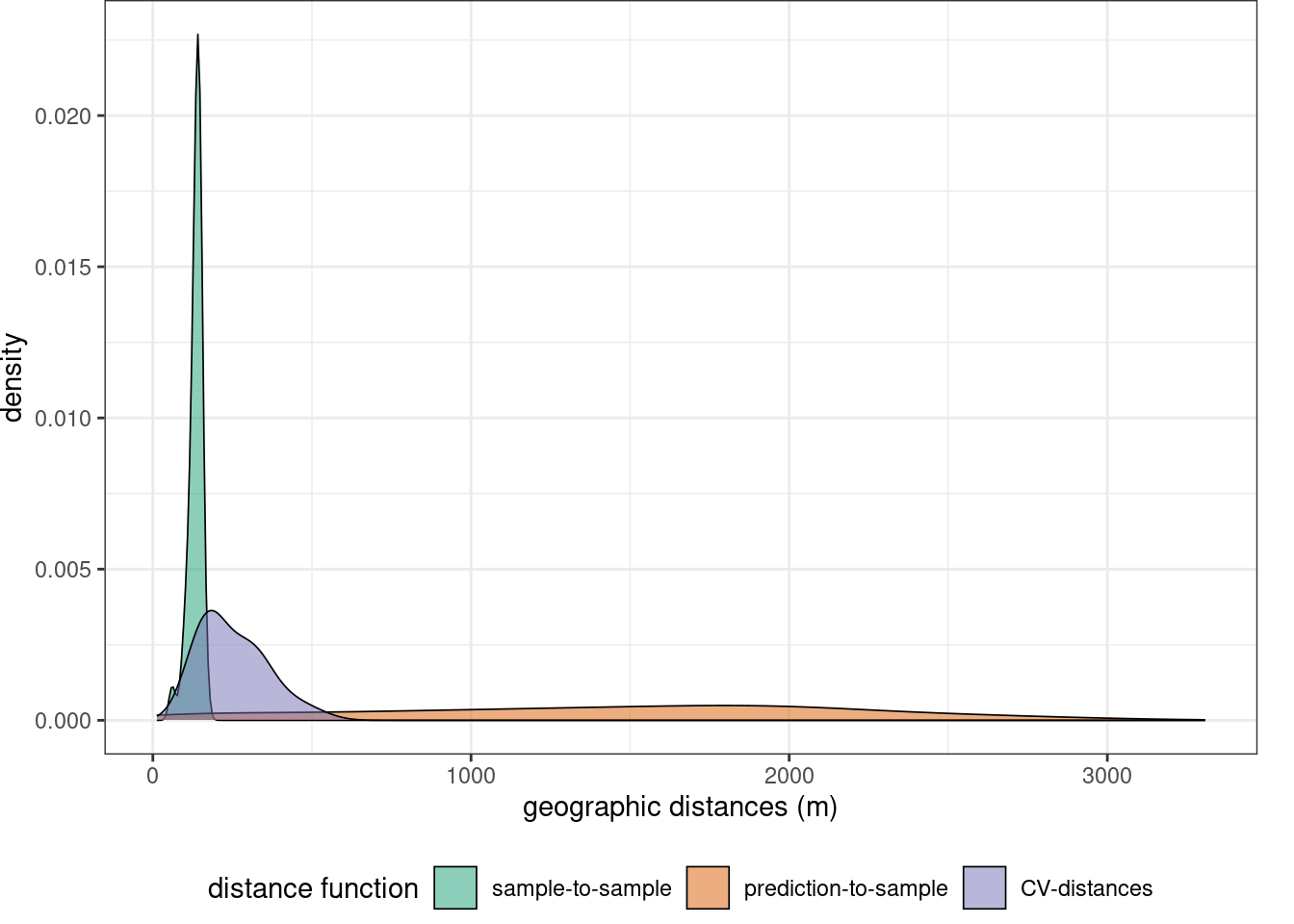
Model training
ctrl <- trainControl(method="cv",
index=nndm_folds$indx_train,
indexOut = nndm_folds$indx_test,
savePredictions = "all")
model_rf <- train(trainDat[,2:11],
trainDat$LAI,
method = "rf")
model <- ffs(trainDat[,predictors],
trainDat$LAI,
method="rf",
trControl = ctrl,
importance=TRUE,
verbose=FALSE)modelSelected Variables:
T32UMB_20170510T103031_B07 T32UMB_20170510T103031_B08 NDVI T32UMB_20170510T103031_B06
---
Random Forest
67 samples
4 predictor
No pre-processing
Resampling: Cross-Validated (10 fold)
Summary of sample sizes: 41, 44, 49
Resampling results across tuning parameters:
mtry RMSE Rsquared MAE
2 0.8533611 0.2020988 0.6960254
3 0.8593941 0.1849834 0.7006255
4 0.8710427 0.1781848 0.7125621
RMSE was used to select the optimal model using the smallest value.
The final value used for the model was mtry = 2.LAI prediction
Let’s then use the trained model for prediction.
LAIprediction <- predict(mof_sen,model)
plot(LAIprediction)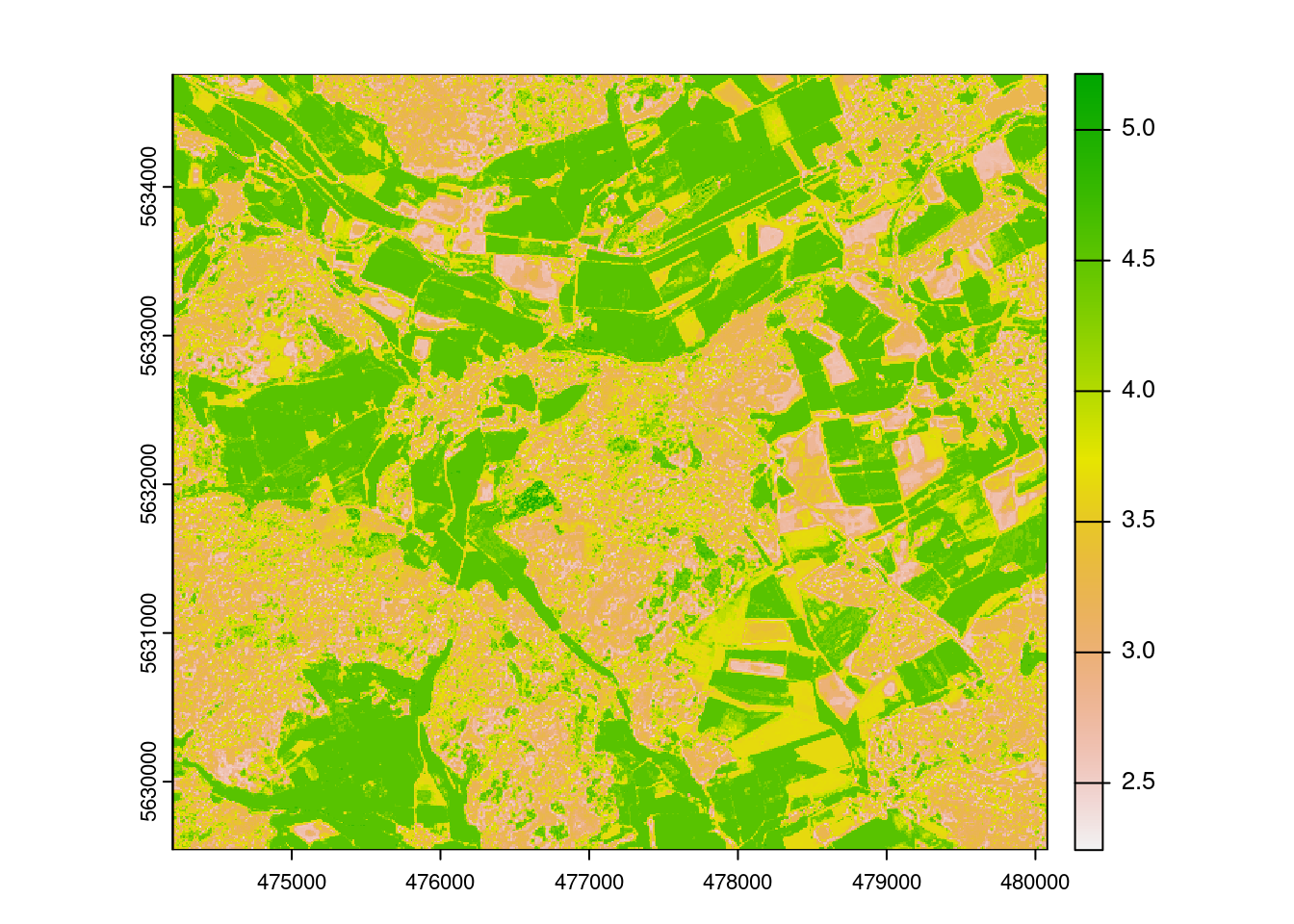
Question?! Why does it look so different than the linear model?
AOA estimation
AOA <- aoa(mof_sen,model_rf)
|
| | 0%
|
|= | 1%
|
|== | 3%
|
|=== | 4%
|
|==== | 6%
|
|===== | 7%
|
|====== | 9%
|
|======= | 10%
|
|======== | 12%
|
|========= | 13%
|
|========== | 15%
|
|=========== | 16%
|
|============= | 18%
|
|============== | 19%
|
|=============== | 21%
|
|================ | 22%
|
|================= | 24%
|
|================== | 25%
|
|=================== | 27%
|
|==================== | 28%
|
|===================== | 30%
|
|====================== | 31%
|
|======================= | 33%
|
|======================== | 34%
|
|========================= | 36%
|
|========================== | 37%
|
|=========================== | 39%
|
|============================ | 40%
|
|============================= | 42%
|
|============================== | 43%
|
|=============================== | 45%
|
|================================ | 46%
|
|================================= | 48%
|
|================================== | 49%
|
|==================================== | 51%
|
|===================================== | 52%
|
|====================================== | 54%
|
|======================================= | 55%
|
|======================================== | 57%
|
|========================================= | 58%
|
|========================================== | 60%
|
|=========================================== | 61%
|
|============================================ | 63%
|
|============================================= | 64%
|
|============================================== | 66%
|
|=============================================== | 67%
|
|================================================ | 69%
|
|================================================= | 70%
|
|================================================== | 72%
|
|=================================================== | 73%
|
|==================================================== | 75%
|
|===================================================== | 76%
|
|====================================================== | 78%
|
|======================================================= | 79%
|
|======================================================== | 81%
|
|========================================================= | 82%
|
|=========================================================== | 84%
|
|============================================================ | 85%
|
|============================================================= | 87%
|
|============================================================== | 88%
|
|=============================================================== | 90%
|
|================================================================ | 91%
|
|================================================================= | 93%
|
|================================================================== | 94%
|
|=================================================================== | 96%
|
|==================================================================== | 97%
|
|===================================================================== | 99%
|
|======================================================================| 100%plot(AOA$AOA)