In this tutorial we will work with a Sentinel-2 scene from 18/06/2022 from the National Park, Harz. We will also use the boundary of the National Park to define our study area. Before we can start you may download the S2 Scene from the following link: S2-download. Place this file into the data folder of this tutorial.
# create a string containing the current working directorywd=paste0(find_rstudio_root_file(),"/tdv_session/data/")#Import the boundary of the nnp_boundary =st_transform(st_read(paste0(wd,"nlp-harz_aussengrenze.gpkg")),25832)
Reading layer `nlp-harz_aussengrenze' from data source
`/home/creu/edu/courses/EON/EON2024/tdv_session/data/nlp-harz_aussengrenze.gpkg'
using driver `GPKG'
Simple feature collection with 1 feature and 3 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 591196.6 ymin: 5725081 xmax: 619212.6 ymax: 5751232
Projected CRS: WGS 84 / UTM zone 32N
Anaylsing the spectral variablity within the study area
If we have no access to prior information on our target variable in the study area we can use the spectral variability as a proxy for the variability of the target variable. By using the spectral variability as a sampling criterion we also ensure, that we cover the spectral range with our sampling.
Dimension reduction (PCA)
In a fist step we reduce the dimensions of the 9 Sentinel-2 bands while maintaining most of the information, using a principal component analysis (PCA).
Warning in matrix(z, nrow = nrow(rr), ncol = ncol(rr), byrow = TRUE):
Datenlänge [168814] ist kein Teiler oder Vielfaches der Anzahl der Zeilen [684]
From the output of the PCA we see that we can capture 92% of the variability with the first two components. Thus we will only use the PC1 and PC2 for the subsequent analysis.
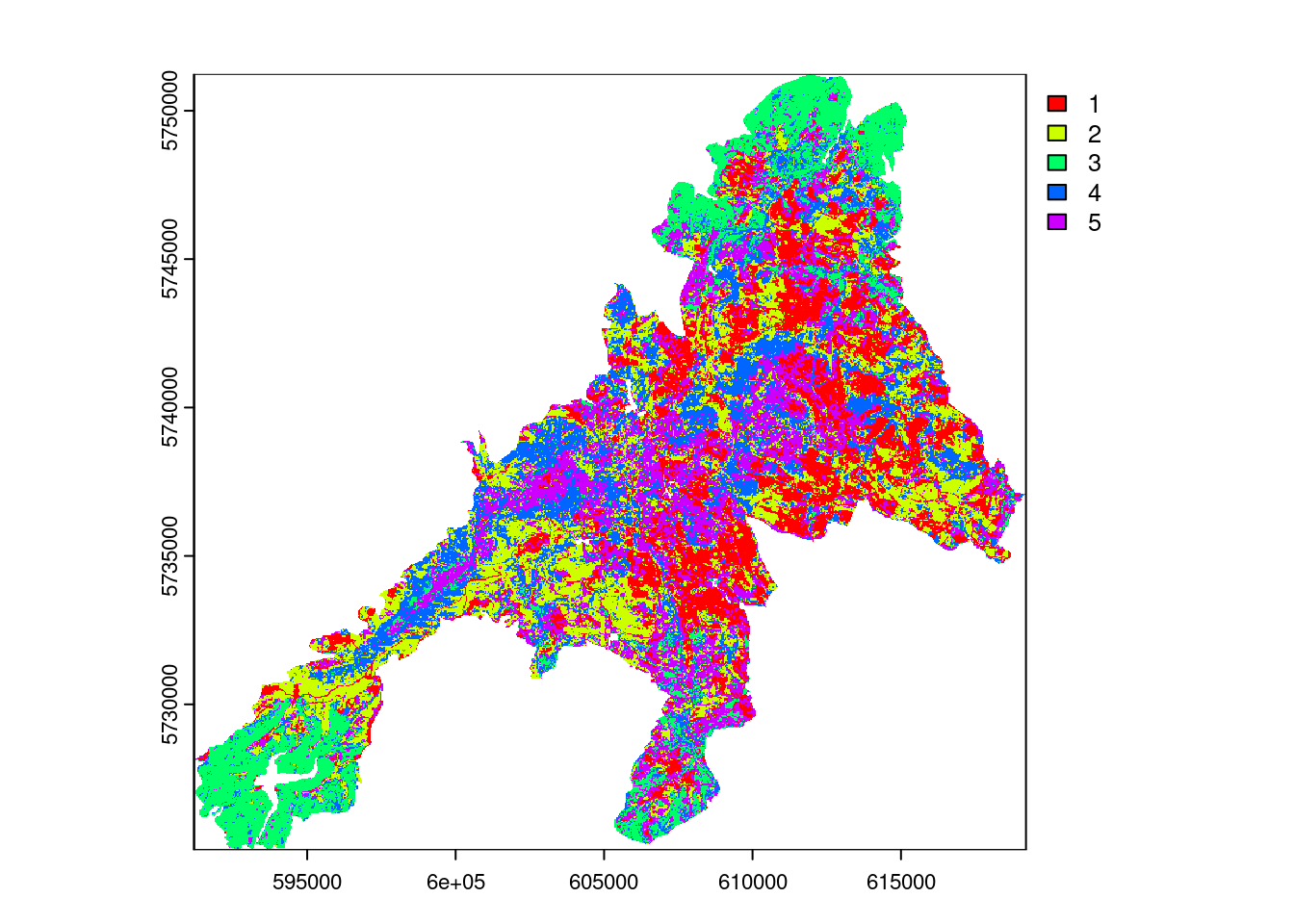
Unsupervised clustering
In the next step we run an unsupervised classification of the PC1 and PC2 to get a clustered map. For the unsupervised classification we need to take a decision on the number of classes/clusters to be created. Here we will take n=5 classes. However, depending on the target variable this value need to be adjusted.
# Create a training data set by extracting the mean value of all pixels touching# a buffered area with 13m around the plot centertrain<-raster::extract(s2,samples,sp=T,buffer=13,fun='mean')mapview(train, zcol="class_unsupervised",map.types =c("Esri.WorldShadedRelief", "OpenStreetMap.DE"))+mapview(np_boundary,alpha.regions =0.2, aplha =1)
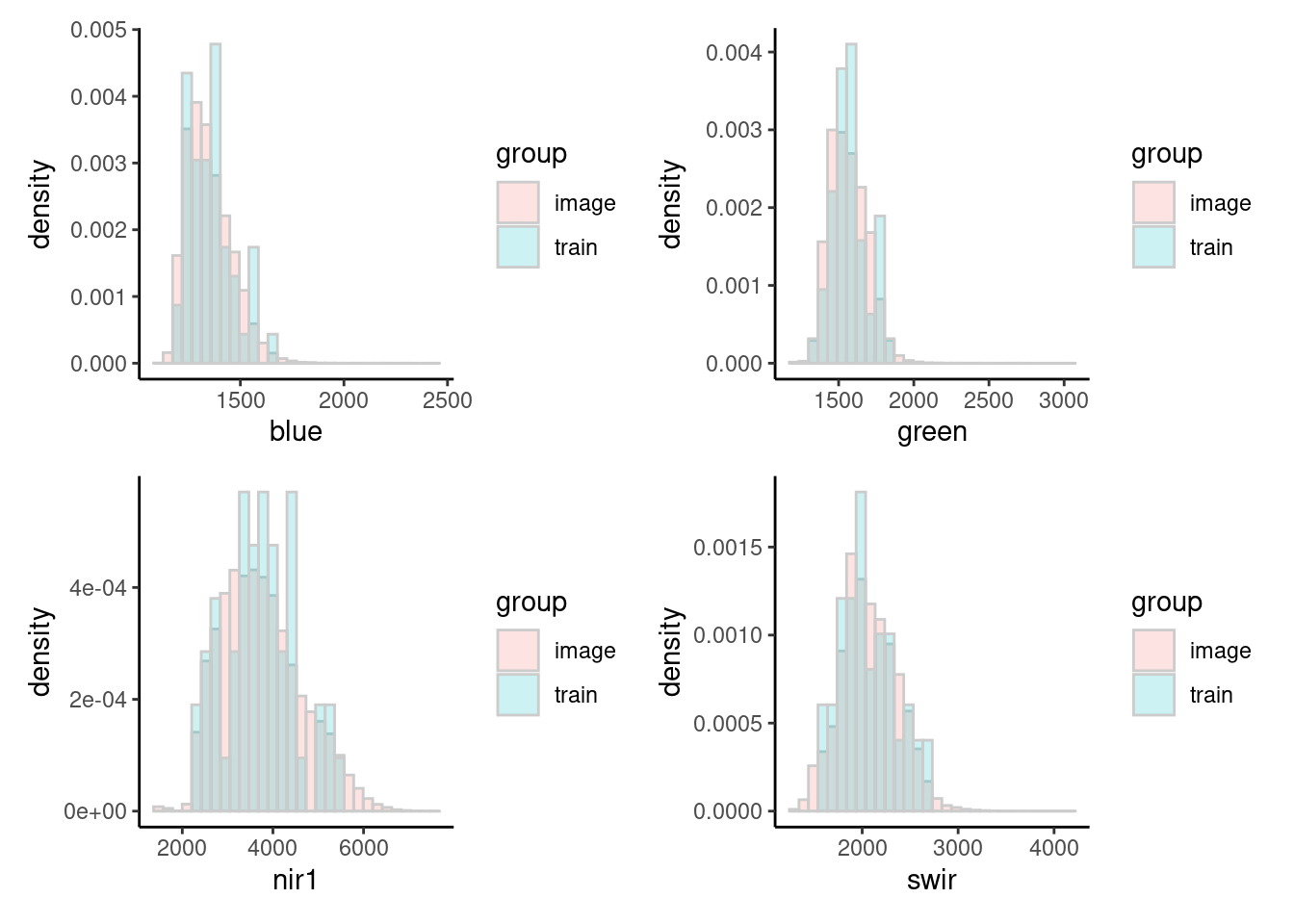
Compare the pixel value range between the sample and the image