
Informationsloser Raum – Distanz-basierte Interpolation
Betrachten Sie als Einstieg eine andere Darstellung der Ihnen bereits bekannten Abbildung der Niederschlagsmesstationen din der Schweiz. Der obere Teil zeigt Ihnen eine eine 3D Niederschlagsoberfläche. Die blauen Punkte sind erneut die Positionen der Messstationen, ihre Größe entspricht der Niederschlagsmenge. Die unterschiedlichen Höhen der Oberfläche sowie ihre Farbgebung stehen ebenfalls in Zusammenhang mit der Niederschlagsmenge. Im unteren teil sehen sie die 2D Verortung der Messtationen innerhalb der Schweiz.
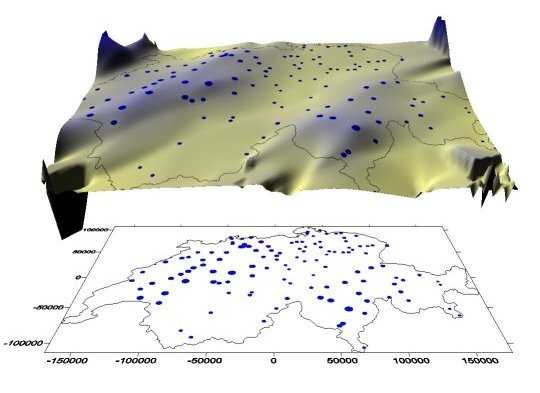
Steht man vor der Aussage aus den einzelnen Punktbeobachtungen flächenhafte Daten zu erzeugen stehen die folgenden Fragen im Vordergrund:
- Wie kann aus den ca. 100 Messpunkten solch eine kontinuierliche Oberfläche erstellt werden?
- Welches Wissen ist nötig und welche Methoden existieren dazu?
- Welche Werkzeuge helfen uns dabei?
In oben gezeigtem Beispiel ist die Variable der Niederschlag. Stellen Sie sich vor, Sie könnten den Niederschlag entlang einer Messstrecke auf jeder beliebigen Position messen. Sie hätten also eine räumlich-kontinuierliche Messung. Benachbarte Niederschlagswerte werden entweder identisch sein oder geringfügig variieren, je nach der gewählten Skala der „Nachbarschaft“. In der Praxis ist quasi jedes natürliche räumlich-kontinuierliche Phänomen von stochastischen Schwankungen bestimmt und lässt sich daher mathematisch nur annäherungsweise beschreiben.
Wie beginnen wir nun mit der Analyse kontinuierlicher Variablen?
Der erste Schritt besteht in der Erstellung einer räumlichen Stichprobe. In dem zu Beginn erwähnten Beispiel des Schweizer Niederschlags sind dies meteorologische Messstationen. Ihre Positionen sind in diesem Fall fest vorgegeben und nicht frei wählbar. Wenn Sie aber z.B. die Verteilung chemischer Schadstoffe im Boden analysieren wollen, müssen Sie zunächst die Messpunkte an denen Sie die Proben entnehmen festlegen. Dabei werden Sie auf folgende Eigenschaften der Stichprobe achten müssen:
- Repräsentativität: Das Phänomen, das analysiert wird, sollte in allen Ausprägungen in der Stichprobe vertreten sein. Insbesondere Minima und Maxima sind von Bedeutung. Für das Niederschlagsbeispiel bedeutet dies: Stationen mit Spitzenwerten sollten vertreten sein. Wenn wir allerdings ein eigenes Probenschema planen, wissen wir in der Regel nicht, ob wir die Standorte mit Minima und Maxima erfasst haben.
- Homogenität: Wie zu Beginn erwähnt, ist die räumliche Abhängigkeit der Daten untereinander eine sehr wichtige Grundvoraussetzung für eine weitere sinnvolle Analyse. Dieser Zusammenhang sollte aber über das gesamte Untersuchungsgebiet homogen sein! Um bei den Niederschlagswerten zu bleiben: jeweils zwei Stationen im Abstand von z.B. 2km sollten sowohl im Tessin ähnliche Messwerte aufweisen als auch im Jura, in Graubünden oder in Fribourg usw.. Diese Voraussetzung nennt man auch „Stationarität“.
- Räumliche Verteilung der Messungen: Die räumliche Verteilung ist von großer Bedeutung. Sie kann völlig zufällig sein, regelmäßig oder geclustert. Die Verteilungen sehen Sie an Beispielen weiter unten im Abschnitt „Typologie“. Einen Hinweis auf die räumliche Verteilung einer Stichprobe können wir statistisch z.B. mittels der „Nearest Neighbor“-Statistik erhalten. Sie zählt zu den „Point Pattern Analysis“-Techniken – Methoden, mit deren Hilfe sich die räumliche Verteilung von Punkten statistisch charakterisieren und analysieren lassen.
- Größe (= Anzahl der Messungen): Die Größe, also der Umfang einer Stichprobe, ist abhängig vom Phänomen und von der Arealfläche. In manchen Fällen unterliegt die Wahl der Stichprobengröße praktischen Einschränkungen. Denken Sie z.B. an Messungen in schwer zugänglichem Gelände, technisch aufwendigen und teuren Messungen usw.. Eine ideale Größe für jegliche Aufgabe anzugeben, ist schlicht unmöglich.
Repräsentativität, Homogenität, räumliche Verteilung und Größe hängen zusammen. So ist eine Größe von 5 Messstationen für die Schätzung des gesamtschweizerischen Niederschlags wohl kaum sinnvoll, daher auch nicht repräsentativ. Ebenso wenig repräsentativ wäre die Auswahl aller deutschschweizerischen Messstationen für die gesamtschweizerische Schätzung. Hier könnte wohl die Größe allein ausreichend sein, nicht aber die räumliche Verteilung. Wählen Sie nun alle Stationen unter 750 mNN aus, so könnte die Stichprobe zwar sowohl von der Größe her als auch von ihrer räumlichen Verteilung stimmen, das Phänomen ist jedoch nicht homogen in der Stichprobe repräsentiert. Eine nachfolgende Schätzung würde v. a. im Bereich von Gebieten über 750 mNN deutlich verzerrt ausfallen.
Räumliche Interpolation von Daten
Nachdem wir zuvor knapp den Zusammenhang räumlicher Abhängigkeiten dargestellt haben, kommen wir nun zu räumlichen Interpolationen. Was sind räumliche Interpolationen? Darunter versteht man die Berechnung unbekannter Werte auf der Basis benachbarter bekannter Werte. Die meisten dieser Techniken zählen zu den komplexeren Methoden räumlicher Analyse, darum beschränken wir uns hier bewusst auf einen prinzipiellen Überblick zu den Methoden.
Inverse Distanz-Gewichtung, Spline-Interpolationen, Kriging-Methoden,Polynomial-Regression-Methoden sind lediglich einige sehr gängige Interpolations-Methoden, die in GIS-Software zu finden sind.
Lokale vs. Globale Interpolation
Globale Methoden werden auf ALLE Daten im Untersuchungsgebiet angewandt, lokale dagegen nur auf räumlich definierte Subsets. Globale Interpolation eignet sich daher nicht zur Ermittlung möglichst exakter Werte, sondern zur Beurteilung globaler räumlicher Strukturen.
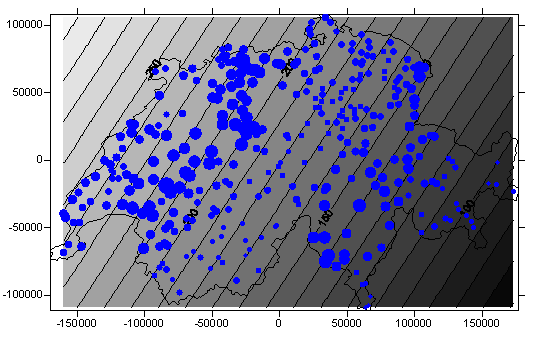
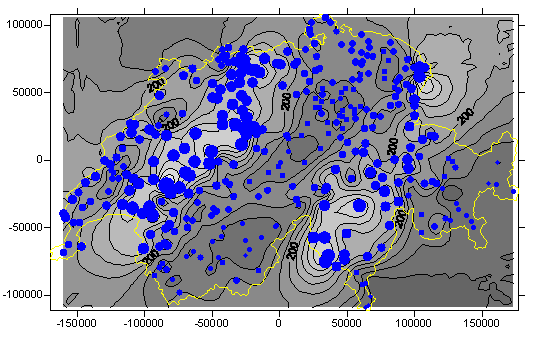
Als Beispiele sehen Sie nachfolgend eine lineare Trend-Oberfläche – sie wurde mittels Regression aus den schweizerischen Niederschlagsdaten ermittelt und zeigt einen Trend zum Anstieg der Niederschlagshöhen von SE nach NW. In der darunter befindlichen Abbildung wird auf den gleichen Daten eine lokale Interpolation mittels sogenannter Radial-Basis-Interpolation durchgeführt.
Exakte vs. Nicht-exakte Interpolation
Exakte Interpolation heißt: die geschätzte Oberfläche passiert die bekannten Punkte, während bei nicht-exakten Methoden die Schätzwerte für bekannte Beobachtungen von den realen Werten abweichen können. Letztere Methoden werden sinnvollerweise dann eingesetzt, wenn die bekannten Daten bereits gewisse Unschärfen aufweisen.
Räumliche Anwendung
Nutzen Sie die interaktiven Möglichkeiten und vergleichen Sie die je nach Verfahren unterschiedlichen räumliche Ausprägungen der flächenhaften Niederschlagsverteilung aus Punktmesswerten. Vergleichen Sie insbesondere die Voronoi-Polygone mit den zum Teil erheblich komplexeren Interpolationsergebnissen. Schalten Sie die Hintergrundkarte z.B. auf Esri.World.Topo.Map und vergleichen Niederschlag und Relief.
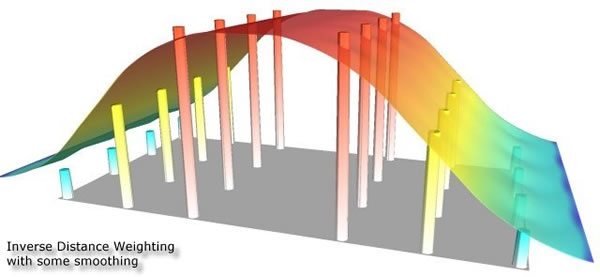
Die dargestellten Beispiele visualisieren die Ergebnisse unterschiedlicher, etablierter Interpolationsverfahren. Aus diesen soll stellvertretend neben der bereits bekannten Voronoi-Tessellation die Inverse Distance-Weighted Interpolation aufgrund ihrer Einfachheit und häufigen Anwendung gesondert betrachtet werden. Bei der Inversen Distanz-Gewichtung (Inverse Distance Weighting, IDW), wird das Gewicht jedes bekannten Punktes invers proportional zu seiner Entfernung zum nächsten Punkt gesetzt und somit hat die Entfernung zum beinflussenden Meßpunkt einen erheblichen Einfluss auf den zwischen Diesen Punkten zu bestimmenden Wert.
Je niedriger der Exponent gesetzt wird, desto gleichförmiger gehen alle Nachbarn (ungeachtet ihrer Distanz) in die Berechnung ein, und desto „glatter“ wird die Schätzoberfläche. Je höher der Exponent wird, desto akzentuierter und „unruhiger“ wird die Oberfläche, da nur mehr das Gewicht der nächstgelegenen Nachbarn in die Interpolation einfließt. Die Methode ist dieam häufigsten verwendete räumliche Interpolationsmethode mit folgenden Stärken:
- Sie ermöglicht sehr schnelle Berechnungen
- Unterschiedliche Distanzen fließen in die Schätzung unterschiedlich ein
- Über den Distanzgewichtungs-Exponent kann der Einfluss der Distanzen fein gesteuert werden
und Schwächen:
- Es ist keine richtungsabhängige Gewichtung möglich, d. h. räumlich gerichtete Zusammenhänge werden ignoriert (z.B. Höhenpunkte entlang eines Bergrückens).
- Neigung zu Artefaktebildung -die sogenannten Bull-Eyes – dies sind kreisförmige Bereiche gleicher Werte um die bekannten Datenpunkte.