Von Punktmessungen zur flächigen Schätzung
Viele geographische Phänomene werden nur an einzelnen Orten gemessen. Niederschlagsstationen, Bodenproben, Temperaturfühler oder Pegel liefern punktuelle Beobachtungen. Für viele Fragestellungen reicht diese punktuelle Information aber nicht aus. Häufig wird eine flächenhafte Darstellung benötigt: Wo ist der Niederschlag hoch, wo niedrig? Welche Bereiche liegen zwischen bekannten Messwerten? Wie kann aus einzelnen Beobachtungen eine räumlich kontinuierliche Schätzung entstehen?
Interpolation bezeichnet die Schätzung unbekannter Werte zwischen bekannten Messpunkten. Sie erzeugt eine Fläche, die nicht direkt beobachtet wurde, sondern aus Punktdaten und Modellannahmen abgeleitet wird. Damit ist jede Interpolation mehr als eine technische Zeichenoperation. Sie entscheidet, wie Nähe, Ähnlichkeit, räumliche Abhängigkeit und Unsicherheit verstanden werden.
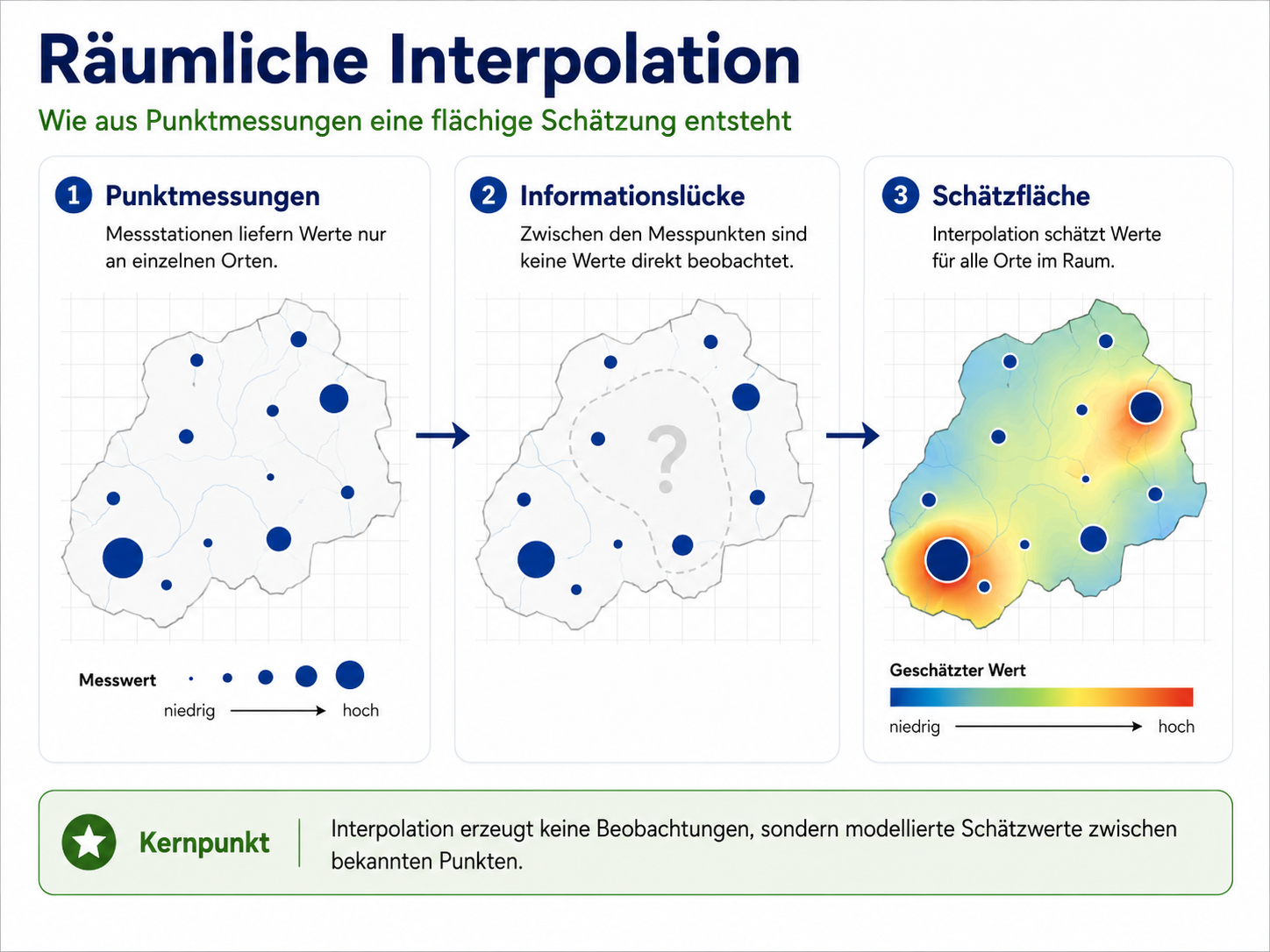
Der zentrale Übergang lautet also:
Punktdaten sind Beobachtungen. Interpolierte Flächen sind modellierte Schätzungen.
Diese Unterscheidung ist wichtig. Eine interpolierte Niederschlagskarte sieht oft geschlossen und eindeutig aus. Tatsächlich zeigt sie aber nicht überall gemessene Werte, sondern eine räumliche Annahme darüber, wie sich Werte zwischen den Stationen verhalten.
Was eine Interpolation voraussetzt
Die Qualität einer Interpolation hängt nicht nur vom gewählten Verfahren ab. Sie hängt zuerst von den Punktdaten ab. Wenn wichtige Räume, Höhenlagen oder Wertebereiche in der Stichprobe fehlen, kann auch ein aufwendig berechnetes Verfahren keine zuverlässige Fläche erzeugen.
Vier Punkte sind besonders wichtig:
Repräsentativität bedeutet, dass die Messpunkte das untersuchte Phänomen ausreichend abdecken. Für eine Niederschlagskarte der Schweiz wäre es problematisch, wenn nur Stationen aus Tieflagen verwendet würden. Dann wären alpine Niederschlagsmuster kaum vertreten.
Räumliche Verteilung beschreibt, wie die Messpunkte im Untersuchungsraum angeordnet sind. Gleichmäßig verteilte Punkte stützen eine Flächenschätzung besser als stark geclusterte Punkte mit großen Lücken.
Homogenität oder Stationarität beschreibt die Annahme, dass räumliche Zusammenhänge im Untersuchungsgebiet vergleichbar sind. Wenn zwei Stationen in 2 km Entfernung in einem Tal ähnlich sind, muss das nicht automatisch auch für zwei Stationen in 2 km Entfernung an einer alpinen Luv-Lee-Grenze gelten.
Anzahl der Messpunkte bestimmt, wie stark eine Methode überhaupt räumliche Muster erfassen kann. Zu wenige Punkte erzwingen sehr grobe Annahmen. Viele Punkte helfen aber nur dann, wenn sie den Raum und das Phänomen sinnvoll abdecken.
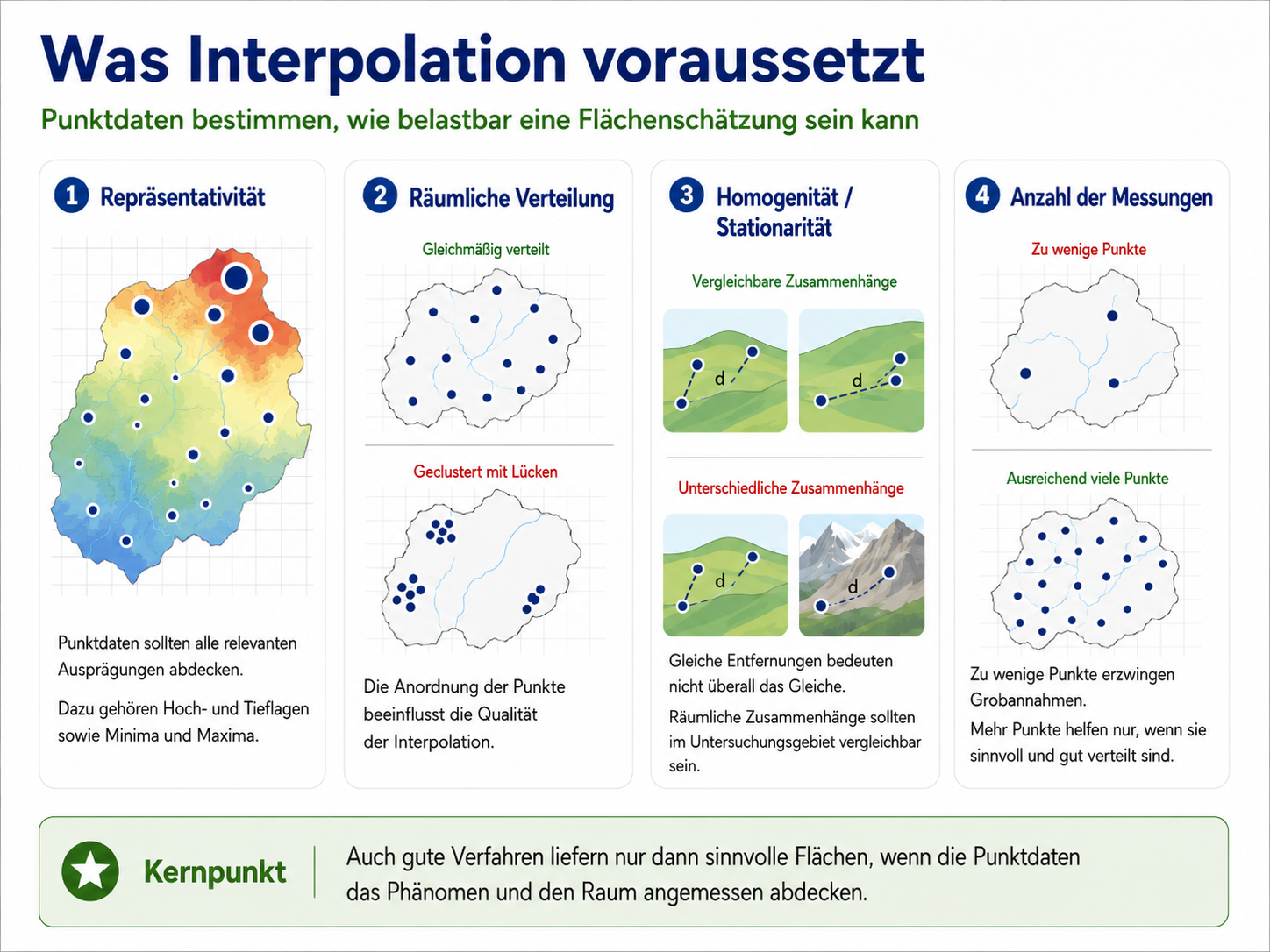
Diese Kriterien hängen zusammen. Fünf Messstationen reichen für eine landesweite Niederschlagsschätzung kaum aus. Eine große Zahl von Stationen kann aber ebenfalls ungeeignet sein, wenn sie fast nur in gut zugänglichen Tälern liegen. Dann wäre die Stichprobe groß, aber für das Gebirge nicht repräsentativ.
Interpolation als Modellentscheidung
Verschiedene Interpolationsverfahren erzeugen aus denselben Punktdaten unterschiedliche Flächen. Der Unterschied liegt nicht nur in der Rechenmethode, sondern in der jeweiligen Raumannahme.
Voronoi-Polygone ordnen jeden Ort dem nächstgelegenen Punkt zu. Das ist keine Interpolation im engeren Sinn, sondern eine Zuordnung nach nächster Distanz. Die Fläche springt abrupt von einem Stationswert zum nächsten.
Inverse Distanzgewichtung, häufig IDW genannt, nimmt an, dass nahe Punkte stärker wirken als entfernte Punkte. Der geschätzte Wert entsteht aus einem gewichteten Mittel benachbarter Messwerte. Nähe wird dabei mathematisch als abnehmender Einfluss mit wachsender Distanz formuliert.
Globale Verfahren, etwa Trendflächen, suchen ein übergeordnetes räumliches Muster. Sie sind geeignet, wenn eine großräumige Richtung oder ein allgemeiner Gradient sichtbar gemacht werden soll. Lokale Details werden dabei bewusst geglättet.
Lokale glatte Verfahren passen sich stärker an Nachbarschaften an. Sie können lokale Muster besser darstellen, sind aber empfindlich gegenüber Punktverteilung, Suchradius, Glättung und Parametereinstellungen.
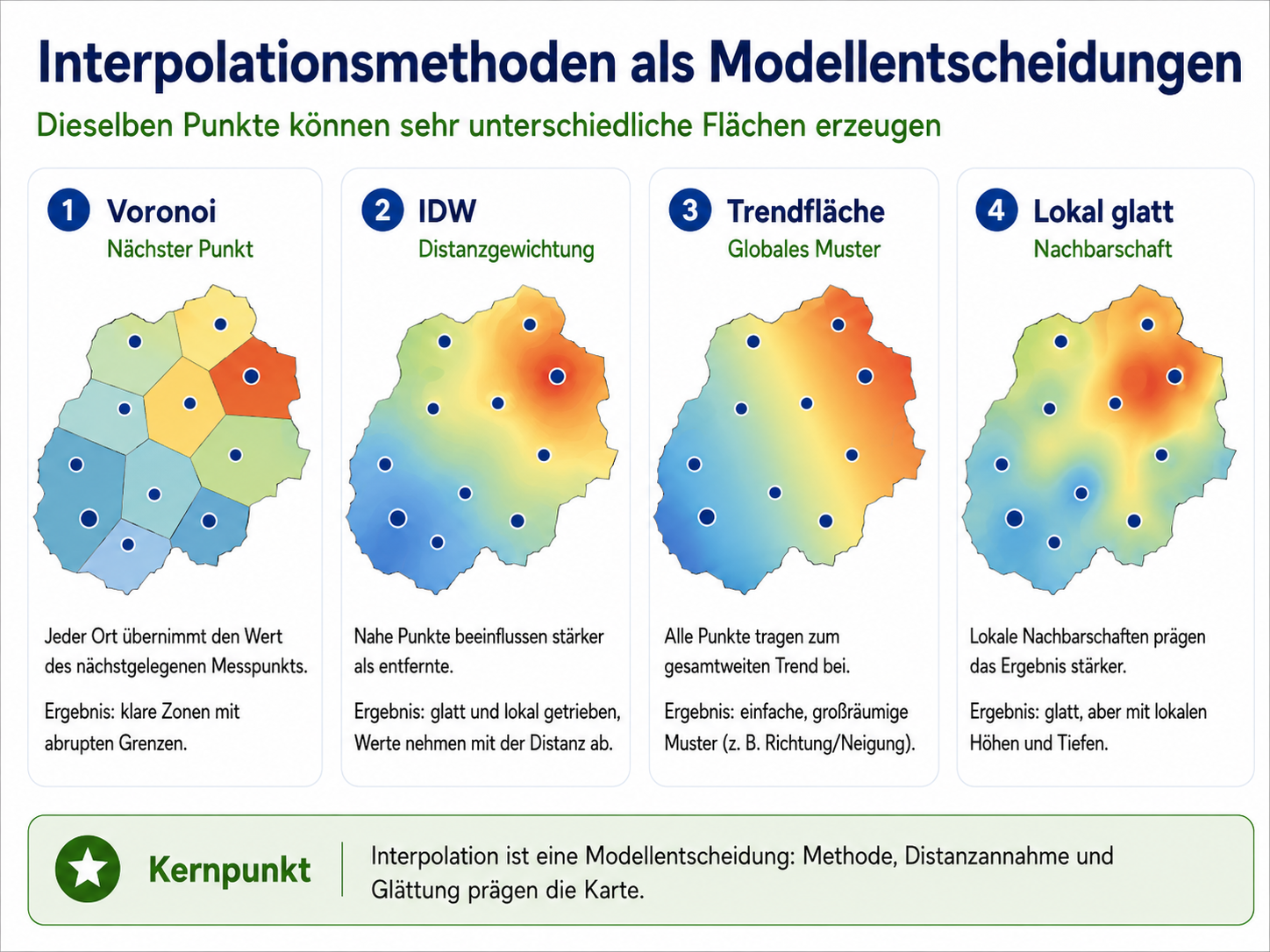
Der entscheidende Punkt ist: Es gibt nicht die eine automatisch richtige Interpolationsmethode. Eine Methode ist nur im Verhältnis zur Fragestellung, zum Phänomen, zur Datenlage und zur gewünschten Aussage angemessen.
Globale und lokale Interpolation
Eine wichtige Unterscheidung betrifft die Frage, welche Messpunkte in die Schätzung eingehen.
Globale Interpolationsverfahren nutzen alle Messpunkte des Untersuchungsgebiets. Dadurch entstehen Oberflächen, die vor allem großräumige Trends sichtbar machen. Für die Niederschlagsdaten der Schweiz könnte eine globale Trendfläche zum Beispiel eine allgemeine Zunahme oder Abnahme in eine bestimmte Richtung zeigen. Solche Flächen sind nicht dafür gedacht, lokale Werte möglichst exakt vorherzusagen. Sie dienen eher dazu, übergeordnete räumliche Strukturen zu erkennen.
Lokale Interpolationsverfahren nutzen dagegen nur Punkte in einer definierten Umgebung oder gewichten nahe Punkte deutlich stärker. Dadurch können lokale Unterschiede besser sichtbar werden. Gleichzeitig hängt das Ergebnis stärker davon ab, wie groß die Nachbarschaft gewählt wird und wie die Messpunkte verteilt sind.
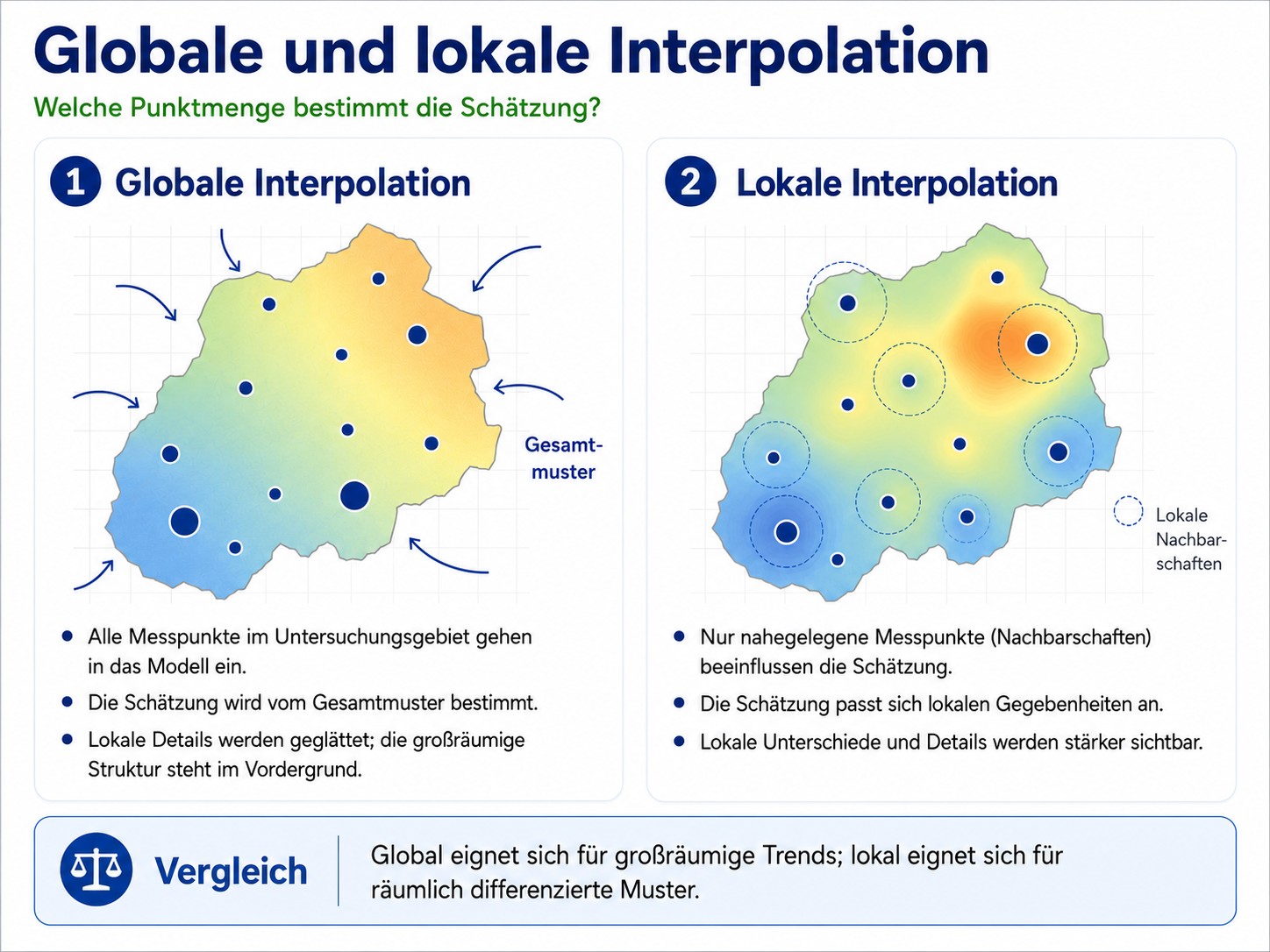
Beide Ansätze beantworten unterschiedliche Fragen. Wer ein großräumiges Muster sucht, benötigt keine detailreiche lokale Oberfläche. Wer lokale Unterschiede zwischen Tälern, Höhenlagen oder Siedlungsräumen untersuchen will, braucht dagegen ein Verfahren, das räumliche Nachbarschaften angemessen berücksichtigt.
Exakte und nicht-exakte Interpolation
Eine zweite wichtige Unterscheidung betrifft die Frage, ob die geschätzte Oberfläche die bekannten Messwerte exakt treffen muss.
Exakte Interpolation bedeutet, dass die Oberfläche an den Messpunkten genau durch die beobachteten Werte läuft. Am Ort der Messstation wird also exakt der gemessene Wert reproduziert. Das ist plausibel, wenn die Messwerte als zuverlässig gelten und keine Glättung gewünscht ist.
Nicht-exakte Interpolation bedeutet, dass die geschätzte Oberfläche die Messpunkte nicht zwingend exakt trifft. Das kann sinnvoll sein, wenn Messwerte unsicher sind, kurzfristige Störungen enthalten oder wenn ein geglättetes räumliches Muster gesucht wird. Die Methode behandelt die Punkte dann nicht als fehlerfreie Wahrheit, sondern als Beobachtungen mit möglicher Unsicherheit.
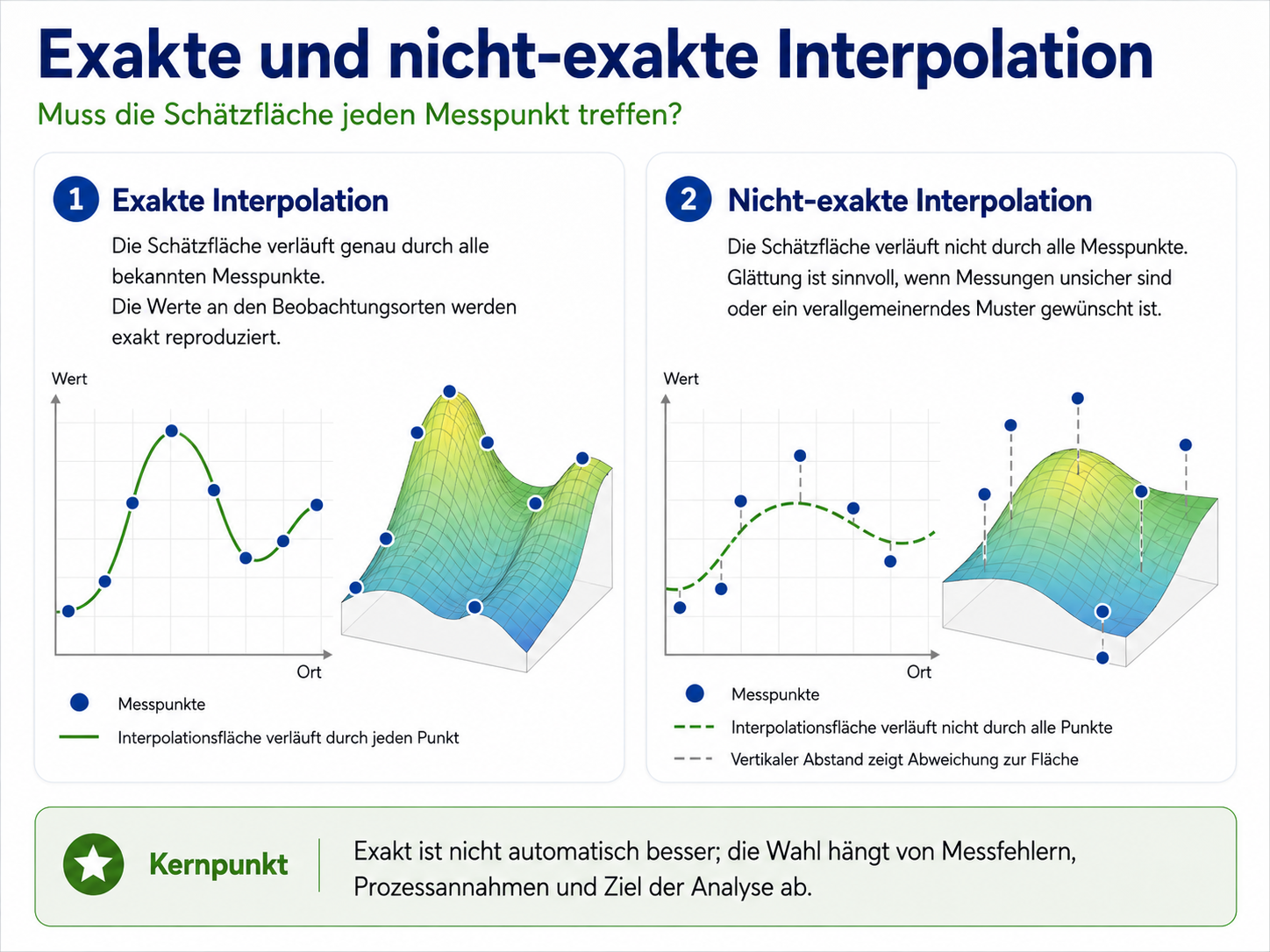
Exakt ist daher nicht automatisch besser. Bei sehr zuverlässigen Messwerten kann eine exakte Methode sinnvoll sein. Bei verrauschten oder kurzfristig schwankenden Daten kann eine geglättete, nicht-exakte Methode fachlich angemessener sein.
Beispiel: Niederschlagsstationen in der Schweiz
Das folgende Beispiel verwendet klimatologische Niederschlagsstationen in der Schweiz. Die blauen Punkte zeigen die Stationen. Die Punktgröße steht für die mittlere langjährige Niederschlagsmenge an der jeweiligen Station. Aus diesen punktuellen Beobachtungen werden verschiedene flächenhafte Darstellungen berechnet.
Die Karte ist besonders geeignet, um die Wirkung verschiedener Verfahren zu vergleichen. Voronoi-Polygone übertragen den Wert der nächstgelegenen Station auf eine ganze Fläche. IDW erzeugt kontinuierlichere Übergänge, weil mehrere Stationen in die Schätzung eingehen. Globale und lokale Verfahren betonen wiederum unterschiedliche räumliche Muster.
Abbildung 04-08: Interaktive Karte der Niederschlagsstationen und interpolierten Niederschlagsflächen in der Schweiz. Die Karte zeigt, wie unterschiedliche Verfahren aus denselben Punktdaten unterschiedliche Flächen erzeugen.
Gerade bei Niederschlag muss die Karte kritisch gelesen werden. Niederschlag hängt nicht nur von der Nähe zur nächsten Station ab. Relief, Höhe, Exposition, Luv- und Lee-Lagen, Talräume und großräumige Wetterlagen beeinflussen die räumliche Verteilung. Deshalb lohnt es sich, in der Karte die Hintergrunddarstellung zu wechseln und die interpolierten Flächen mit der Topographie zu vergleichen.
Achten Sie besonders auf folgende Fragen:
- Wo liegen große Lücken zwischen Stationen?
- Welche Flächen werden stark von einzelnen Stationen geprägt?
- Wo folgen die interpolierten Muster erkennbar der Topographie?
- Wo wirken Grenzen oder Gradienten eher wie ein methodischer Effekt?
- Welche Methode erzeugt eine plausible Fläche, und welche erzeugt nur eine formal glatte Darstellung?
Übung: Interpolationsmethoden vergleichen
Kernpunkt
Räumliche Interpolation übersetzt punktuelle Beobachtungen in flächenhafte Schätzungen. Diese Schätzungen sind nie neutral. Jede Methode enthält Annahmen darüber, wie Werte zwischen Messpunkten zusammenhängen. Eine gute Karte entsteht deshalb nicht nur durch ein Werkzeug, sondern durch die passende Verbindung von Daten, Methode, Prozessverständnis und kritischer Interpretation.